In one week, the 2015 edition of Strata Conference (or rather: Strata + Hadoop World) will open its doors to data scientists and big data practitioners from all over the world. What will be the most important big data technology trends for this year? As last year, I ran an analysis on the Strata abstract for 2015 and compared them to the previous years.
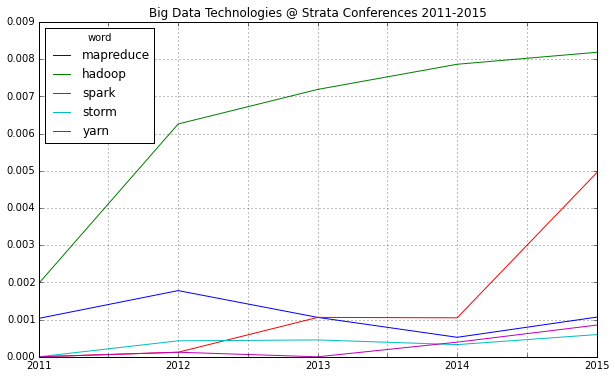
One thing immediately strikes: 2015 will be probably known as the “Spark Strata”:
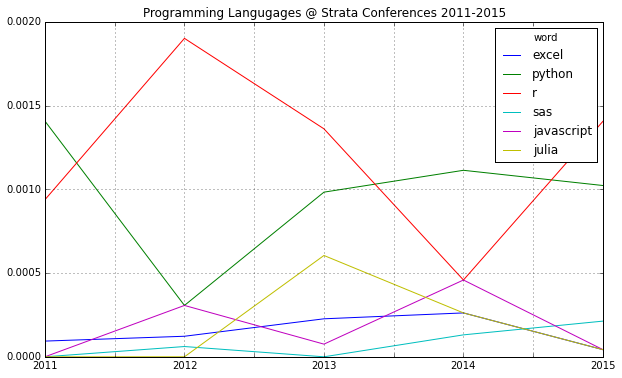
If you compare mentions of the major programming languages in data science, there’s another interesting find: R seems to have a comeback and Python may be losing some of its momentum:
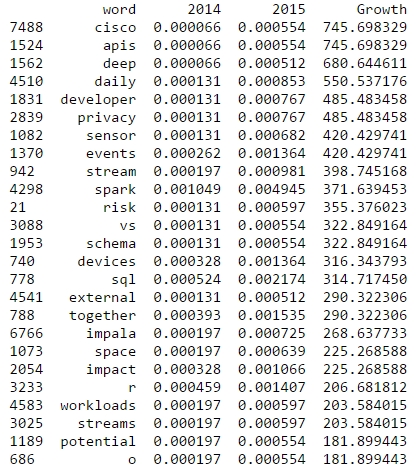
R is also among the rising topics if you look at the word frequencies for 2015 and 2014:
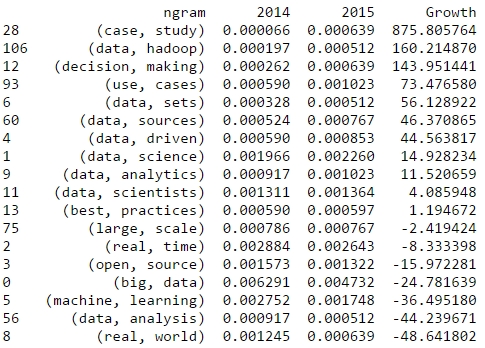
Now, let’s take a look at bigrams that have been gaining a lot of traction since the last Strata conference. From the following table, we could expect a lot more case studies than in the previous years:
This analysis has been done with IPython and Pandas. See the approach in this notebook.
Looking forward to meeting you all at Strata Conference next week! I’ll be around all three days and always in for a chat on data science.
Abstract: Data is the new media. Thus the postulates of our Slow Media Manifesto should be applicable on Big Data, too. Slow Data in this sense is meaningful data, relevant for society, driving creativity and scientific thinking. Slow Data is beautiful data.
From Slow Media to Slow Data
Five years ago we wrote the Slow Media Manifesto. We were concerned about the strange dichotomy by which people separated old media from new media to make their point about quality, ethics, and aesthetics. With Big Data, I now encounter a similar mindset. Just like people were scoffing social media to be just doodles, scribbling, or worse, I now see people scornfully raising their eyebrows about the lack of structure, missing consistency, and other alleged flaws they imagine Big Data to carry. As if “good old data” with a small sample size, representativeness, and other formalistic criteria would be a better thing as such. Again what these people see is just an evil new vice swamped over their mature businesses by unseasoned startups however, insanely well funded. I have gone through this argument twice already. It was wrong in the 90s when the web started, it was wrong again in the 2000s regarding social media, and it will not become right this time. Because it is not the technology paradigm that makes quality.
A mathematician, like a painter or a poet, is a maker of patterns. If his patterns are more permanent than theirs, it is because they are made with ideas. Beauty is the first test: there is no permanent place in the world for ugly mathematics.
Godfrey Harold Hardy
Data is the new media. I have written about this, too. The traditional concept of media becomes more and more directly intertwined with data, with data storytelling, data journalism, and their likes, indirectly because search, targeted advertising, content filtering, and other predictive technologies increasingly influence what we will find presented as media content.
Therefore I think it makes sense to take Slow Media and ask about Slow Data, too.
Highly curated small data
For what is useful above all is technique.
Godfrey Harold Hardy
Direct marketing data sets tend to be not very high quality (sorry CRM folks, but I know what I am talking about). Many records are only partly qualified, if at all. Moreover, the information on which the targeting is based is often outdated.
Small samples can enhance large heaps of data
In 2006 I oversaw a major market survey, the Typologie der Wünsche. This very expensive market research was conducted diligently according to the rules of the trade of social science. The questionnaire went through the toughest lectorship before it would be considered ready to be send out to the interviewers. The survey was done face to face, based on a cautiously drawn sample of 10.000 people per year. The results underwent permanent quality assurance. To be sure about the quality of the survey it was conducted by three independent research agencies. By doing this we could cross check plausibility.
Since my employer was also involved in direct marketing with a huge database of addresses, call centers, and logistics, we developed a method to use the highly curated market survey with its rather small sample to calibrate and enhance the “dirty” records of the CRM business. This was working so well that we started a cooperation with Deutsche Post to do the same, but on a much larger scale. Our small but precious data was matched with all 40 million addresses in Germany.
When working for MediaCom I was involved with a similar project. Television ratings are measured by expensive panels in most markets, usually run and funded by joint industry committees like BARB in the UK or AGF in Germany. Of course such a panel is restricted to just a few thousand households. Since in traditional broadcasting there are only some ten relevant TV channels in any market, this panel size is sufficient to support media planning. But internet usage is so much more fragmented that a panel of that sort would hardly make sense. So we took the data that we had collected via web tracking – again some 40 million records. We again found a way to infuse the TV panel data into the online data and could by that calculate the probabilities that the owner of a certain cookie would have had contact with a certain advertising campaign on TV or not. And again a small but highly curated and very specialized data set was used to greatly increase the value of the larger Big Data set.
Bringing scientific knowledge into Big Data
Archimedes will be remembered when Aeschylus is forgotten, because languages die and mathematical ideas do not.
Godfrey Harold Hardy
Another example where small but highly curated data is crucial for data science are data sets that contain scientific information which otherwise is not inherent in the data. Text mining works best when you can use quantitative methods without thinking about those difficult cultural concepts like ‘meaning’ or ‘semantics’. Detection of relevant content with ngram ranking, or text comparison based on cosine vector distance are the most powerful tools to analyze texts even in unfamiliar languages or alphabets. However, all the quantitative text mining procedures require the text to be preprocessed: All vocabulary with only grammatical function that would not add to the meaning has to be stripped off first. It is also useful to bring the words to their root form (picture verbs into infinitive, nouns into nominative singular). This indispensable work is done with special corpora, dictionaries, or better call it libraries, that contain all the required information. These corpora are handmade by linguists. Packages like Python’s NLTK have them incorporated in a handy way.
I am interested in mathematics only as a creative art.
Godfrey Harold Hardy
“Beautiful evidence” is what Edward Tufte calls good visualization. Information can truly be brought to us in a beautiful way. Data visualization as an art form had also entered the Sanctum of high arts when the group Asymptote was presented at Documenta 11 in 2002. Visual storytelling today has transformed. What used to be cartoons or engravings like this one here to illustrate the text, is now infographics that are the story.
Generative art is another data-driven art format. When I was an undergraduate The Fractal Geometry of Nature had finally tickled down to the math classes. With my Atari Mega ST I devoured all fractal code snippets I could get into my hands. What fascinated me most were not the (usually rather kitschy) colorful fractal images. I wanted to have fractal music, generative music that would evolve algorithmically from my code.
Although fractals as an art-thing where certainly more a fad, not well suited to turn into real art, generative art as such has since then become a strong branch in the Arts. Much of today’s music relies heavily on algorithmic patterns in many of its dimensions, from rhythm to tune, to overtone spectra. Also in video art, algorithmically rendered images are ubiquitous.
Art from data will further evolve. I trust we will see data fiction become a genre of its own.
Data as critique
… there is no scorn more profound, or on the whole more justifiable, than that of the men who make for the men who explain. Exposition, criticism, appreciation, is work for second-rate minds.
Godfrey Harold Hardy
Critique is the way to think in the alternative. Critique means not to trust what is sold to you as truth. Data is always ambiguous. Meaning is imposed upon data by interpretation. Critique is to deconstruct interpretation, to give room for other ways to interpret. The other stories we may draw from our data do not have to be more plausible, at all. Often the absurd is what unveils hidden aspects of our models. As long as our alternative interpretations are at least possible, we should follow these routes to see where they end. Data fiction is the means to turn data into a tool of critique.
Data science has changed our perception of how lasting we take our results to be. In data science we usually do not see a conclusion as true or permanent. Rather we hope that a correlation or pattern that we observe will remain stable, at least for a while. There is no hypothesis that we would accept and then tick off just because our test statistics turned significant. We would always continue to a/b-test alternative models, that would substitute an earlier winner of the test-game. In data science, we maximize critical thinking by not even seeing what we do as falsification because we would not have thought of the previous state as true in the first place. Truth in data science means just the most plausible interpretation at a time; ephemeral.
Slow Data accordingly means to use data to deconstruct the obvious, as well as to built alternatives.
Ethical data
A science is said to be useful if its development tends to accentuate the existing inequalities in the distribution of wealth, or more directly promotes the destruction of human life.
Godfrey Harold Hardy
The two use cases that dominate the discussion about Big Data are the right opposite of ethical: Targeted advertising, and mass surveillance. As Bruce Sterling points out, both are in essence just two aspects of the same thing that he calls ‘surveillance marketing’. I feel sad that this is what seams to be the prominent use of our work: To sell things to people who do not want them, and to keep people down.
However, I am confident that the benign uses of Big Data will soon offer such high incentive that we will awake from our military marketing nightmares. With open data we build a public space. All the most useful Big Data tools are all in the pubic domain anyway: Hadoop, Mesos, R, Python, Gephy, etc. etc.
Ethical data is data that makes a difference for society. Ethical data is relevant for people’s lives: To control traffic, to make agriculture more sustainable, to supply energy, to help plan cities and administer the states. This data will be crucial to facilitate our living together with ten billion people.
Slow Data is data that makes a difference for people’s lives.
Political data
It is never worth a first class man’s time to express a majority opinion. By definition, there are plenty of others to do that.
Godfrey Harold Hardy
“Code is Law” is the catch phrase of Lawrence Lessig famous bestseller on the future of democracy. From the beginning of the Internet revolution, there has been the discussion, whether our new forms of media and communication would lead to another revolution as well: a political one. Many of the media and platforms that rose over last decade show aspects of communal or even social systems – and hence might be called Social Media with good cause. It does not come as a surprise that we start to see the development of the communication platforms that are genuinely meant to support and at the same time to experiment with new forms of political participation, like Proxy-Voting or Liquid Democracy, which had been hardly conceivable without the infrastructure of the Web. Since these new forms of presenting, debating, and voting for policies have been started occurring just recently we can expect that many other varieties will appear, new concepts to translate the internet paradigm into social decision making. Nevertheless, how do these new forms of voting work? Are they really mapping the volonté generale into decisions? If so, will it work in a sustainable, stable, continuous way? And how to evaluate the systems, one compared to another? I currently work in a scientific research project on how to deal with these questions. Today I am not yet ready to present conclusions. Nonetheless, I already see that using data for quantitative simulation is a good approach to approximate the complex dynamics of future data-driven political decision-making.
Politics as defined by Aristotle means to have the freedom to make decisions based on ethics and beliefs and not driven by necessities, the latter is what he calls economics. To deal with law in this sense is similar to my text mining example above. If law is codified, it can be executed syntactically, indeed quite similar to a computer program. But to define what is just, what should be put into the laws, is not syntactical, at all. Ideally this would be exclusively political. I don’t think, algorithmic legislation would be desirable, I doubt that it would be even feasible.
Slow Data means to use data to explore new forms of political participation without rush.
Machine thinking
Chess problems are the hymn-tunes of mathematics.
Godfrey Harold Hardy
‘Could a machine think?’ is the core question of AI. The way we think about answering this question immediately lead us beyond computer science: What does it mean to think? What is consciousness? Since the 1980s there has been a fascinating exchange of arguments about the possibility of artificial intelligence, culminating in the Chinese Room debate between John Searle and the Churchlands. Searle and in an even more abstract way, David Chalmers made good points why a simulation of consciousness that would even pass the Turing test, would never become really conscious. Their counterparts, most prominent Douglas Hofstadter, would reject Chalmers neo-Kantianism as metaphysics.
Google has recently published an interesting paper on artificial visual intelligence. They trained mathematical models with random pictures from social media sites. And – surprise! – their algorithm came up with a concept of “What is a cat?”. The point is, nobody had told the algorithm to look for cat-like patterns. Are we witnessing the birth of artificial intelligence here? On the one hand, Google’s algorithm seams to do exactly what Hofstadter predicted. It is adaptive to environmental influences and translates the sensory inputs into something that we interpret as meaning. On the other side was the training sample far from random. The pictures were what people had pictured. It was a collaboratively curated set of rather small variety. The pattern the algorithm found was in fact imposed by “classic” consciousnesses, by the minds of “real” people.
Slow Data is the essence that makes our algorithm intelligent.
The beauty of scientific data
Beauty is the first test: there is no permanent place in this world for ugly mathematics.
Godfrey Harold Hardy
Now returning to Hardy’s quote from the beginning, when I was studying mathematics I was puzzled by the strange aestheticism that many mathematicians would force upon their train of thoughts. Times have changed since then. Today we have many theorems solved that were considered hard problems. Computational proofing has taken its role in mathematical epistemology. Proofs filling thousands of pages are not uncommon.
Science, physics in particular, is driven by accurate data. Kepler could dismiss the simple heliocentric model because Tycho Brahe had measured the movements of the planets to such accuracy that the model of circular orbits could no longer be maintained. Edwin Hubble discovered the structure of our expanding universe because Milton Humason and other astronomers at Mt. Wilson had provided for spectroscopic images of thousands of galaxies, exact enough to derive Hubble’s constant from the redshift of the prominent Fraunhofer lines. Einstein’s Special Theory of Relativity relies on the data of Michelson and Morley who had shown that light would travel at constant speed, no matter the angle to the direction of our earth’s travel around the sun it was measured against. Such uncompromisingly accurate data, collected in a painstaking struggle without any guarantee to pay off – this is what really brought the great breakthroughs in science.
Finally, while mathematics is turning partially into syntax, the core of physics at the same time unfolds in the strange blossoms of the most beautiful mathematics imaginable. In the intersect of cosmology, dealing with the very largest objective imaginable – the entirety of the cosmos, and quantum physics on the smallest scale lies the alien world of black holes, string theory, and quantum gravity. The scale of these phenomena, the fabric of space-time is likely defined by relating Planck’s constant to Newton’s constant and the speed of light is so unimaginably small – some 40 powers of magnitude smaller than the size of an electron – that we can’t expect to measure any data even near to it any time soon. We can only rely on our logic, our sense for mathematical harmony, and the creative mind.
Slow Data
Slow Data – for me the space of beautiful data is spanned by these aspects. I am confident that we do not need an update to our manifesto. However, I hope that we will see many examples of valuable data, of data that helps people, that creates experiences unseen, and that opens the doors to new worlds of our knowledge and imagination.
Appendix: Slow Media
The Slow Media movement was kicked off with the Slow Media Manifesto that Sabria David, Benedikt Koehler and I had written on new year’s day 2010. Immediately after we had published the manifesto, it was translated into Russian, French, and some other 20 languages.
I already mentioned the Hastie & Tibshirani course on statistical learning as one of my personal highlights in data science last year. My second highlight is also an online course, also by leading experts on their field (this time: Big Data and data mining), also based on a (freely available) book and also by Stanford University professors: Jure Leskovec, Anand Rajamaran and Jeff Ullman’s course on “Mining Massive Datasets”.
If you’re interested in data science or data mining, chances are high that you have already been in touch with their book. It can safely be considered a standard work on the fascinating intersection of data mining algorithms, machine learning and Big Data. The 7 week course is the online version of the Stanford courses CS246 and the earlier version of CS345A.
The course is very dense and covers a lot of territory from the book, for example:
How does Map Reduce work and why is it important?
How can I retrieve frequently appearing combinations from very large sets of items such as shopping baskets?
How to retain information about a datastream that does not fit in memory?
What are the most common tasks in supervised machine learning and how to implement them?
How do I program an intelligent system for recommending movies?
How to compute optimal placements of online advertisements?
Some of the lectures are on a beginners to intermediate level, but some lectures cover very advanced topics. What I especially liked about this course is that a lot of the material covered really is state-of-the-art in data mining. Some algorithms – e.g. the BIGCLAM community detection and CUR matrix decomposition – had only been developed about year ago.
So, take a look at the book, and if you haven’t already: enroll at the Coursera course website to make sure you won’t miss the next session of this course.
2014 was a great year in data science – and also an exciting year for me personally from a very inspirational Strata Conference in Santa Clara to a wonderful experience of speaking at PyData Berlin to founding the data visualization company DataLion. But it also was a great year blogging about data science. Here’s the Beautiful Data blog posts our readers seemed to like the most:
Datalicious Notebookmania – My personal list of the 7 IPython notebooks I like the most. Some of them are great for novices, some can even be challenging for advanced statisticians and datascientists
Trending Topics at Strata Conferences 2011-2014 – An analysis of the topics most frequently mentioned in Strata Conference abstracts that clearly shows the rising importance of Python, IPython and Pandas.
Big Data Investment Map 2014 – I’ve been tracking and analysing the developments in Big Data investments and IPOs for quite a long time. This was the 2014 update of the network mapping the investments of VCs in Big Data companies.
How to create a location graph from the Foursquare API – In this post, I explain a way to make sense out of the Foursquare API and to create geospatial network visualizations from the data showing how locations in a city are connected via Foursquare checkins.
Text-Mining the DLD Conference 2014 – A very similar approach as I used for the Strata conference has been applied to the Twitter corpus refering to Hubert Burda Media DLD conference showing the trending topics in tech and media.
“One hundred and sixty eight (68 men and 100 women) undergraduates from a small, private college in Pennsylvania participate d in this study.”
(L. McDermott, T. Pettijohn II: “The Influence of Clothing Fashion and Race on the Perceived Socioeconomic Status and Person Perception of College Students.” Psychology & Society, 2011, Vol. 4 (2) , 64 ‐ 75
Draper: “What do women want?”
Stirling: “Who cares!”
One of my colleagues at Max-Planck-Institut once came to me with a draft paper. It dealt with dimorphism in sexes and would present evidence, that most differences could be explained from genetic heritage. The method that was mandatory practice at this institute was social biology -every behavior should only occur with humans (and animals likewise), if a clear evolutionary advantage could be derived from it. Since it was the early 90s, the fight of science against postmodernism was still at its peak. Postmodernist thinking, like “it could just be our imposing social conventions into our methods to learn what we already knew”, was brusquely brushed away, because “we use the scientific method, don’t we?”.
In the paper, my colleague presented results of some surveys he had conducted that showed correlation of the perceived “beauty” of people on images with the (I forgot how he had quantified it) beauty of the subject’s spouse (I also forgot the thesis he would derive thereof). The correlation was very weak, like R²~0.6 or so. But because he had surveyed several hundred people, it became significant; it proved his absurd postulate.
The scientific method in general, but in quantitative social sciences in particular, has four steps to take:
1. Formulate the hypothesis
2. Draw a representative sample of observations
3. Test the hypothesis and prove it significant
4. Publish the results for review.
For now I do not want to focus on the strange reviewing practices that do not really publish results but rather keep them within closely confined boundaries of scientific journals, inaccessible for the public, only available for a small academic elite, so that a sound review hardly takes place.
I want to discuss the first three steps, because during the last 20 years, my professional field has undergone a dramatic paradigm shift, regarding these, while the forth is still holding for the time being.
The quantitative methods in social science originate from the age of the mass society within a nation state. These methods were developed as tools to help management and politics with their decisions. Alternatives to be tested were usually simple. The industrial production process would not allow for subtile variations in the product, thus it would be sufficient to present very few – usually two – varieties to the survey’s subjects. People’s lives would be likewise simple: a teacher’s wife would show a distinctive consumption pattern, as would a coal miner. It would be good enough to know people’s age, gender, and profession to generalize from one specimen to the whole group. Representativeness means, that one element of a set is used to represent the whole set – and not just with the properties, that would characterize the set itself (like male/female, Caucasian/Asian, etc.); the whole set would inherit all properties of its representative. It is counting the set as one, as Alain Badiou puts it.
We are so used to this aggregation of people into homogeneous sets, that we hardly realize its existence anymore. The concept of “target groups” in advertising is justified with this, too. Brands buy advertising by briefing the agency with gender, age, education of the people the campaign should reach. Prominent is the ABC-Audience in the UK, a rough segmentation of the populace just by their buying power and cultural capital.
In the mass society, up to the 1970s, this more or less seemed to make sense. People in their class or milieu would behave sufficiently predictable. Especially television consumption still mirrors this aspect of mass society: ratings and advertising effect could be calculated and even predicted from the TV measurement panels with scientific precision. 2006 I came in charge of managing one of the largest and longest running social surveys, the “Typologie der Wünsche“. Topics covered where consumption, brand preferences, and many aspects of people’s opinions and daily routine, surveyed by personal interview of 10,000 participants per year. Preparing a joint study with Roland Berger Strategy Consultants, I examined the buyers of car brands regarding all aspects of them being defined as a “target group”. The fascinating result was: while in the 1980s to the mid 1990s, buyers of car brands had been indeed quite homogeneous regarding their political opinions, ecological preferences, consumption of other brands, etc., this seemed to wane away over the last decade. The variance increased dramatically, so that to speak of “the buyer of a car brand” could be questioned. This was even more true for fast-moving consumer goods. Superficially, this could be explained by daily consumption becoming cheaper in proportion to average income, so poorer consumers where no longer as much restricted to certain goods as in earlier times. But the observation would prevail, even if just people with comparable wealth were taken into account.
Our conclusion: the end of mass media (that my employer was suffering from, like most traditional publishers), might come along with the end of mass society, too. The concept of aggretating people by objective criteria, by properties observable from the outside, like gender, income, or education, was getting under pressure.
For Israeli military strategist Martin van Creveld, this is also the underlying condition for what he calls the “Transfromation of War”. In military philosophy, the corresponding paradigm is the idea of soldiers and civilians, unfolded by von Clausewitz. Van Crefeld argues, that the constructs of Clausewitz’ theory, like ‘peoples’ (‘Völker’) had never existed in the first place. They were just stories told to organize war at industrial scale. And van Crefeld explicitly deconstructs the gender gap in battle. His book is full of quantitative proof that men, just regarded from the physical perspective, would make no better soldiers, than women. The the distributions of women and men in size, weight, physical strength etc. are mainly overlapping. Of course, the mean size of men is taller for a few centimeters than the size of women. This mean difference is significant, if you make a t-test. But as always, a significant mean difference says nothing about the individual. Most women are as tall as most men. Just some men are taller, and some women are smaller.
The fallacy of significance-testing should be obvious. It presumes the subjects would be originating from different universes, disjoint subsets of the population. Testing takes it for granted, that hypothesis and alternative are truly distinct, that only one can hold. This is hardly ever the case when humans are concerned. For most properties that we are studying in social research, the intra-set variance is much bigger than the variance between two sets, be it gender, be it age, education, hair color, or what ever criteria we choose to form the subsets. Women in most aspects are in average less similar one to each other, than the value of the mean difference of women and men.
This given, the logical next question would be, if the method had been correct, at all. The conditions of the industrial age made it only possible to serve their products to aggregates of people. Representative democracy also only gives the choice between a handful party programmes. And mass media could in principle not match individual preferences. So it seemed logic to place people in categories, too, without bothering that dichotomous variables like sex might not be appropriate to map people’s gender. Quantitative social research just reproduced the ideological restrictions of mass society.
With the Web, people suddenly had the choice, not only regarding media, but also regarding consumption. And -surprise!- people do act individually, and the actions are so random, that no correlation holds for more than a couple of weeks. “Multi-optional consumer” is a helpless way to express, that the silos of segmentation no longer make sense. Of course nobody has ever encountered a multi-optional person; on the individual level, people’s behavior is mostly continuous and perfectly consistent; it is just no longer about “what women want”.
The Web also presented for the first time a tool to collect data describing (nearly) everyone on the individual level. However, with trillions of data points on billions of users, every difference between subgroups becomes significant, anyway. Dealing with results like in the example of my colleague’s ethological study mentioned above, the problem comes from taking significance as absolute. No matter how small an effect is, as long as it is significant, it will be considered proven. But statistical inference was designed to suite sample sizes of some ten to some low in the thousands people. It is ill-suited to deal with big data.
The jokes about silly correlations with Google trends are thus totally correct. And this demonstrates also another aspect: significance and hypotheses testing is regarded as static while data remains dynamic. While at some point in time, a correlation of Google trends with other time series might just randomly become significant, it is highly unlikely, that this bogus correlation will survive. Data science, other than classic quantitative research, tends to deal with data in an agile way, which means, that nothing is regarded as fixed. But if we see our data as ephemeral, there is no need to come up with models that we restrict according to fixed proven hypothesis.
So the role of statistics for social science changes. Statistics is now the tool to deal with distributions as phenomena as such rather than just generalizing from small samples to an unknown population. We should use the stream of data as the life-condition in which our models would have to struggle to survive in. Like with biological evolution, we would not expect the assumptions to remain stable. We would rather expect, the boundary conditions to change, and our models would have to adjust; survival of the fittest model means: the fittest for now.
The philosophical justification for inference is the idea of the general comprehensibility of reality. Like St. Augustine we postulate that it is possible to extrapolate from perception (=measurement, data) to the world of things. But like our sensory organs have been evolving, driven by environmental change (and mutations in our genome), we should regard the knowledge we derive from data as “shadow on the cave wall” at best.
This is far better than it sounds: it gives us freedom to explore data rather than just test our made-up hypotheses, that would just perpetuate our presumptions.
Let’s leave statistical testing and significance where it belongs to: Quality assurance, material testing, physical measurements -engineering.
Let’s be honest, and drop it in the humanities.
Monday, I’ll be speaking on “Linked Data” at the 49th German Market Research Congress 2014. In my talk, there will be many examples of how to apply the basic approach and measurements of Social Network Analysis to various topics ranging from brand affinities as measured in the market-media study best for planning, the financial network between venture capital firms and start-ups and the location graph on Foursquare.
Because I haven’t seen many examples on using the Foursquare API to generate location graphs, I would like to explain my approach a little bit deeper. At first sight, the Foursquare API differs from many other Social Media APIs because it just allows you to access data about your own account. So, there is no general stream (or firehose) of check-in events that could be used to calculate user journeys or the relations between different places.
Fortunately, there’s another method that is very helpful for this purpose: You can query the API for any given Foursquare location to output up to five venues that were most frequently accessed after this location. This begs for a recursive approach of downloading the next locations for the next locations for the next locations and so on … and transform this data into the location graph.
I’ve written down this approach in an IPython Notebook, so you just have to find your API credentials and then you can start downloading your cities’ location graph. For Munich it looks like this (click to zoom):
Munich seen through Foursquare check-ins
The resulting network is very interesting, because the “distance” between the different locations is a fascinating mixture of
spatial distance: places that are nearby are more likely to be connected (think of neighborhoods)
temporal distance: places that can be reached in a short time are more likely to be connected (think of places that are quite far apart but can be reached in no time by highway)
affective/social distance: places that belong to a common lifestyle are more likely to be connected
Feel free to clone the code from my github. I’m looking forward to seeing the network visualizations of your cities.
The Sword and Shield – the metaphor for intelligence in the Soviet world, much stronger than NSA’s key-clutching eagle. Let us fight for our cause with our fiery swords of spirit and blind them with our armour of bright data.
“The NSA is basically applied data science.”
Jason Cust
The European Court of Justice declared the EU directive on data retention void the same day #hartbleed caused the grosset panic about password security the Net had seen so far.
This tells one story:
Get out into the open! Stop hiding! There are no remote places. No privileges will keep your data from the public. No genius open source hack will protect your informational self determination. And spooks, listen: your voyerism is not accepted as OK, not even by the law.
We’re living in a world with more transparency, we need to learn to do intelligence with more transparency too.
Bruce Schneier, #unowned
I was fighting against Europe’s data retention directive, too, and of course I was feeling victorious when it was declared void by the ECJ. But, don’t we know how futile all efforts are, to keep data protected? No cypher can be unbreakable, except the one-time-pad (and that is just of academic interest). No program-code can be proven safe, either – these are mathematical facts. Haven’t you learned how wrong all promisses of security are by #heartbleed? Data protection lulls us into feeling save from data breeches, where we should rather care to make things robust, no matter if the data becomes public intentionally or not.
The far more important battle was won the same week, when the European Parliament decided to protect net neutrality by law. This is the real data protection for me: protecting the means of data production from being engrossed in private.
The intelligence agencies’ damaging the Net by undermining the trust of its users in the integrity of its technology, is a serious thing by inself. However burrying this scandal just under the clutter of civil rights or under constitutional law’s aspects will not do justice. It is of our living in societies in transition from the modern nation state to the after-modern … what ever, liquid community; into McLuhan’s Global Village which is much more serious and much more interesting. We will have to go through the changes of the world and it might not be nice all the time until we come out the other end.
Data begs to be used.
Bruce Schneier, #unowned
In “Snow Crash”, Neal Stephenson imagines a Central Intelligence Corporation, the CIA and NSA becoming a commercial service where everybody just purchases the information they’d need. This was, what came immediately to my mind when I read through the transcript of the talk on “Intelligence Gathering and the Unowned Internet” that was held by the Berkman Center for Internet and Society at Harvard, starring Bruce Schneier, who for every Mathematician in my generation is just the godfather of cryptography. Representatives of the intelligence community were also present. Bruce has been arguing for living “beyond fear” for more than a decade, advocating openness instead of digging trenches and winding up barbed wire. I am convinced, that information does not want to be free (as many of my comrades in arms tend to phrase). However I strongly belief Bruce is right: We can hear data’s call.
The Quantified Self, life-logging, self-tracking – many people making public even their most intimate data, like health, mood, or even our visual field of sight at any moment of our day. An increasingly strong urge to do this rises from social responsibility – health care, climate research, but also from quite profane uses like insurances offering discounts when you let your driving be tracked. So the data is there now, about everything there is to know. Not using it because of fear for privacy would be like having abandond the steam engine and abstinate from the industrialization in anticipation of the climate change.
Speak with us, don’t speak for us.
statement of autonomy of #OccupyWallStreet
Dinosaurs of modern warfare, like the NSA are already escamotating into dragons, fighting their death-match like Smaug at Lake Esgaroth. We have to deal with the dragon, kill it, but this is not, what we should set our political goal to. It will happen anyway.
We should take provision for what real changes we are going to face. We will find ourselves in a form of society that McLuhan would have called re-tribalized, or Tönnies would not have called society at all, but community. In a community, the concept of privacy is usually rather weak. But at the same time, there is no surveillance, no panoptic elevated watchmen who themself cannot be watched. Everyone is every other one’s keeper. Communal vigilance doesn’t sound like fun. However it will be the consequence of after-modern communal structures replacing the modern society. “In the electric world, we wear all mankind as our skin.”, so McLuhan speaketh.
Noi vogliamo cantare l’amor del pericolo.
M5S
Every aspect of life gets quantized, datarized, tangible by computers. Our aggregated models of human behavior get replaced by exact description of the single person’s life and thus the predictions of that person’s future actions. We witness the rise of non-representative democratic forms like occupy assemblies or liquid democracy. What room can privacy have in a world like this whatsoever? So maybe we should concentrate in shaping our data-laden future, rather then protecting a fantasy of data being contained in some “virtual reality” that could be kept separate from our lives.
The data calls us from the depth; let us hear to its voice!
One of the most remarkable features of this year’s Strataconf was the almost universal use of IPython notebooks in presentations and tutorials. This framework not only allows the speakers to demonstrate each step in the data science approach but also gives the audience an opportunity to do the same – either during the session or afterwards.
Here’s a list of my favorite IPython notebooks on machine learning and data science. You can always find a lot more on this webpage. Furthermore, there’s also the great notebookviewer platform that can render Github’bed notebooks as they would appear in your browser. All the following notebooks can be downloaded or cloned from the GitHub page to work on your own computer or you can view (but not edit) them with nbviewer.
So, if you want to learn about predictions, modeling and large-scale data analysis, the following resources should give you a fantastic deep dive into these topics:
If you want to learn how to automatically extract information from Twitter streams, Facebook fanpages, Google+ posts, Github accounts and many more information sources, this is the best resource to start. It started out as the code repository for Matthew’s O’Reilly published book, but since the 2nd edition has become an active learning community. The code comes with a complete setup for a virtual machine (Vagrant based) which saves you a lot of configuring and version-checking Python packages. Highly recommended!
This is another heavy weight among my IPython notebook repositories. Here, Cameron teaches you Bayesian data analysis from your first calculation of posteriors to a real-time analysis of GitHub repositories forks. Probabilistic programming is one of the hottest topics in the data science community right now – Beau Cronin gave a mind-blowing talk at this year’s Strata Conference (here’s the speaker deck) – so if you want to join the Bayesian gang and learn probabilistic programming systems such as PyMC, this is your notebook.
The tutorial session on parallel machine learning and the Python package scikit-learn by Olivier Grisel was one of my highlights at Strata 2014. In this notebook, Olivier explains how to set up and tune machine learning projects such as predictive modeling with the famous Titanic data-set on Kaggle. Modeling has far too long been a secret science – some kind of Statistical Alchemy, see the talk I gave at Siemens on this topic – and the time has come to democratize the methods and approaches that are behind many modern technologies from behavioral targeting to movie recommendations. After the introduction, Olivier also explains how to use parallel processing for machine learning projects on really large data-sets.
Ever wondered how Nate Silver calculated his 2012 presidential election forecasts? Don’t look any further. This notebook is reverse engineering Nate’s approach as he described it on his blog and in various interviews. The notebook comes with the actual polling data, so you can “do the Nate Silver” on your own laptop. I am currently working on transforming this model to work with German elections – so if you have any ideas on how to improve or complete the approach, I’d love to hear from you in the comments section.
This notebook is one of the showcases for the new GraphLab Python package demonstrated at Strata Conference 2014. The GraphLab library allows very fast access to large data structures with a special data frame format called the SFrame. This notebook works on the Freebase movie database to find out whether the Kevin Bacon number really holds true or whether there are other actors that are more central in the movie universe. The GraphLab package is currently in public beta.
The days of holecount and 1000+ pages of statistical tables are finally history. Today, data science and data visualization go together like Bayesian priors and posteriors. One of the hippest and most powerful technologies in modern browser-based visualization is the d3.js framework. If you want to learn about the current state-of-the-art in combining the beauty of d3.js with the ease and convenience of IPython, Brian’s Strata talk is the perfect introduction to this topic.
I found the final notebook through the above mentioned talk. Peter Norvig is not only the master mind behind the Google economy, teacher of a wonderful introduction to Python programming at Udacity and author of many scientific papers on applied statistics and modeling, but he also seems to be the true nerd. Who else would take a xkcd comic strip by the word and work out the regular expression matching patterns that provide a solution to the problem posed in the comic strip. I promise that your life will never be the same after you went through this notebook – you’ll start to see programming problems in almost every Internet meme from now on. Let me know, when you found some interesting solutions!
Open foresight is a great way to look into future developments. Open data is the foundation to do this comprehensively and in a transparent way. As with most big data projects, the difficult part in open foresight is to collect the data and wrangle it to a form that can actually be processed. While in classic social research you’d have experimental measurements or field notes in a well defined format, dealing with open data is always a pain: not only is there no standard – the meaningful numbers might be found anywhere in your source and be called arbitrarily; also the context is not given by some structure that you’d have imposed into your data in advanced (as we used to do it in our hypothesis-driven set-ups).
In the last decade, crowdsourcing has proven to be a remedy to dealing with all kinds of challenges that are still to complex to be fully automatized, but which are not too hard to be worked out by humans. A nice example is zooniverse.org featuring many “citizen science projects”, from finding exoplanets or classifying galaxies, to helping to model global climate history by entering historic ships’ log data.
Climate change caused by humanity might be the best defended hypothesis in science; no other theory had do be defended against more money and effort to disprove it (except perhaps evolution, which has do fight a similar battle about ideology). But apart from the description, how climate will change and how that will effect local weather conditions, we might still be rather little aware of the consequences of different scenarios. But aside from the effect of climate-driven economic change on people’s lives, the change of economy itself cannot be ignored when studying climate and understand possible feedback loops that might or might not lead into local or global catastrophe.
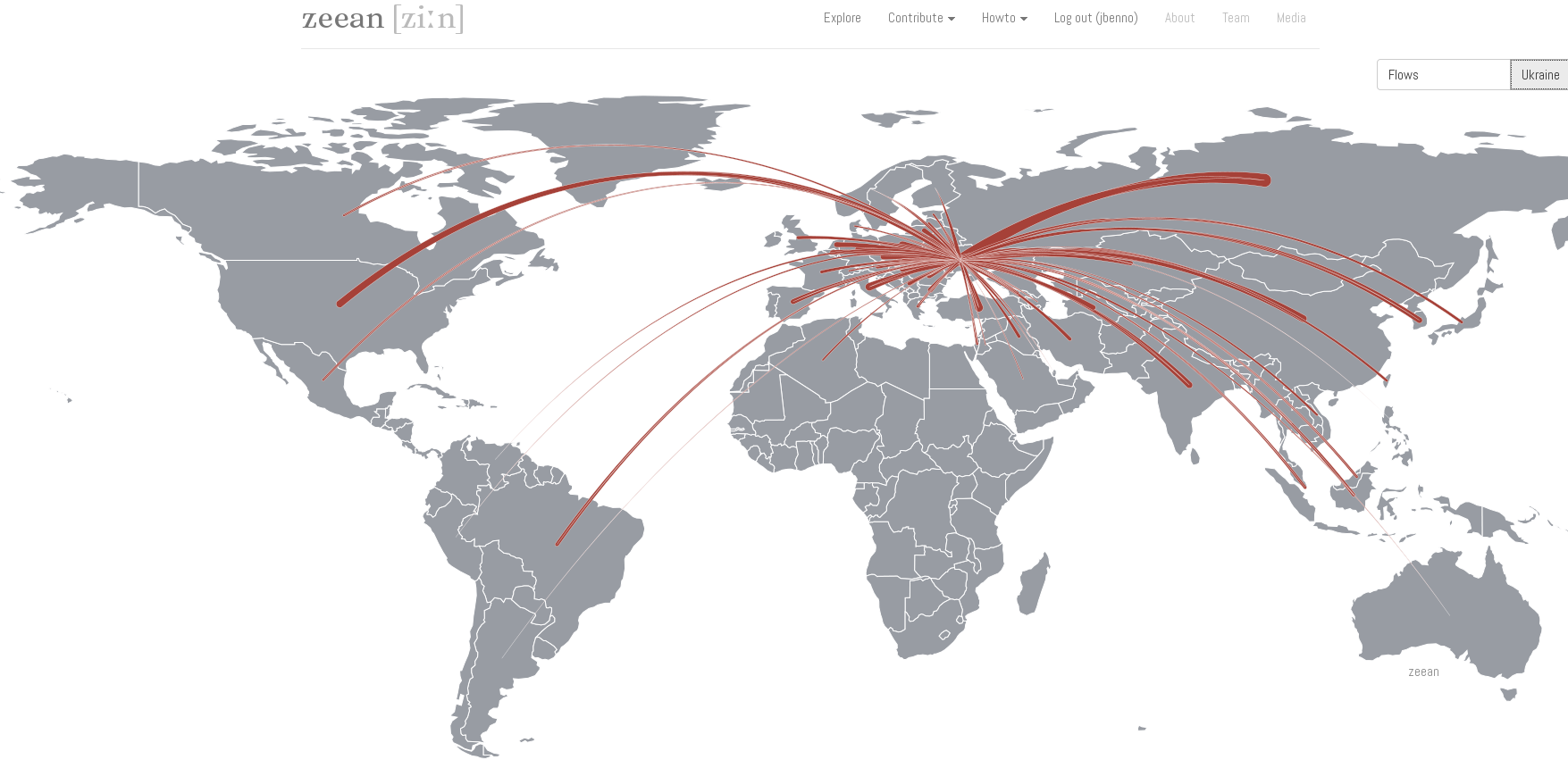
Zeean.net is an open data / open source project aiming at the economic impact of climate change. Collecting data is crowdsourced – everyone can contribute key indicators of geo-economic dependency like interregional and domestic flow of supply and demand in an easy “Wikipedia-like” way. And like Wikipedia, the validation is done by crowd-crosscheck of registered users. Once data is there, it can be fed into simulations. The team behind Zeean, lead by Anders Levermann at Potsdam Institute for Climate Impact Research is directly tied into the Intergovernmental Panel on Climate Change IPCC, leading research on climate change for the UN and thus being one of the most prominent scientific organizations in this field.
A first quick glance on the flows of supply shows how a conflict in the Ukraine effect the rest of the world economically.The results are of course not limited to climate. If markets default for other reasons, the effect on other regions can be modeled in the same way.
So I am looking forward to the data itself being made public (by then brought into a meaningful structure), we could start calculating our own models and predictions, using the powerful open source tools that have been made available during the last years.
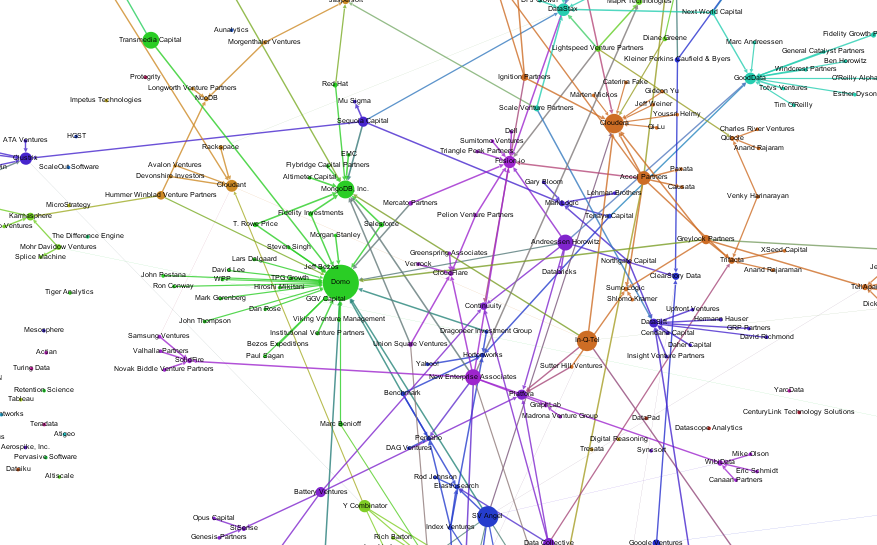
One of the most interesting Big Data companies in this network analysis of Venture Capital connections has in my opinion been Domo. Not only did it receive clearly above average funding for such a young company, but it was also one of the nodes with the best connections through Venture Capital firms and their investments. It had one of the highest values for Betweenness Centrality, which means it connects a lot of the other nodes in the Big Data landscape.
Then, some days after I did the analysis and visualization, news broke that Domo received $125M from Greylock, Fidelity, Morgan Stanley and Salesforce among others. This is a great opportunity to see what this new financing round means in terms of network structure. Here’s Domo before the round:
And this is Domo $125M later. Notice how its huge Betweenness Centrality almost dwarfs the other nodes in the network. And through its new connections it is strongly connected to MongoDB:
Here’s a look at the numbers, before Series C:
Company
Centrality
1
Domo
0.1459
2
Cloudera
0.0890
3
MemSQL
0.0738
4
The Climate Corporation
0.0734
5
Identified
0.0696
6
MongoDB, Inc.
0.0673
7
Greenplum Software
0.0541
8
CrowdFlower
0.0501
9
DataStax
0.0489
10
Fusion-io
0.0488
And now:
Company
Centrality
1
Domo
0.1655
2
MemSQL
0.0976
3
Cloudera
0.0797
4
MongoDB, Inc.
0.0722
5
Identified
0.0706
6
The Climate Corporation
0.0673
7
Greenplum Software
0.0535
8
CrowdFlower
0.0506
9
DataStax
0.0459
10
Fusion-io
0.0442
The new funding round now only increases Domo’s centrality but also MongoDB’s because of the shared investors Salesforce, T. Rowe Price and Fidelity Investments.
The growth does look quite exponential to me. BTW: The early spike in 2007 has been the huge investment in VMWare by Intel and Cisco. Currently, I have not included IPOs and acquisitions in my calculations.
Here’s an updated version of our Big Data Investment Map. I’ve collected information about ca. 50 of the most important Big Data startups via the Crunchbase API. The funding rounds were used to create a weighted directed network with investments being the edges between the nodes (investors and/or startups). If there were multiple companies or persons participating in a funding round, I split the sum between all investors.
This is an excerpt from the resulting network map – made with Gephi. Click to view or download the full graphic:
If you feel, your company is missing in the network map, please tell us in the comments.
The size of the nodes is relative to the logarithmic total result of all their funding rounds. There’s also an alternative view focused on the funding companies – here, the node size is relative to their Big Data investments. Here’s the list of the top Big Data companies:
Company
Funding
(M$, Source: Crunchbase API)
VMware
369
Palantir Technologies
343
MongoDB, Inc.
231
DataStax
167
Cloudera
141
Domo
123
Fusion-io
112
The Climate Corporation
109
Pivotal
105
Talend
102
And here’s the top investing companies:
Company
Big Data funding
(M$, Source: Crunchbase API)
Founders Fund
286
Intel
219
Cisco
153
New Enterprise Associates
145
Sequoia Capital
109
General Electric
105
Accel Partners
86
Lightspeed Venture Partners
72
Greylock Partners
63
Meritech Capital Partners
62
We can also use network analytical measures to find out about which investment company is best connected to the Big Data start-up ecosystem. I’ve calculated the Betweenness Centrality measure which captures how good nodes are at connecting all the other nodes. So here are the best connected Big Data investors and their investments starting with New Enterprise Associates, Andreessen Horowitz and In-Q-Tel (the venture capital firm for the CIA and the US intelligence community).
To fill the gap until this year’s Strata Conference in Santa Clara, I thought of a way to find out trends in big data and data science. As this conference should easily be the leading edge gathering of practitioners, theorists and followers of big data analytics, the abstracts submitted and accepted for Strataconf should give some valuable input. So, I collected the abstracts from the last Santa Clara Strata conferences and applied some Python nltk magic to it – all in a single IPython Notebook, of course.
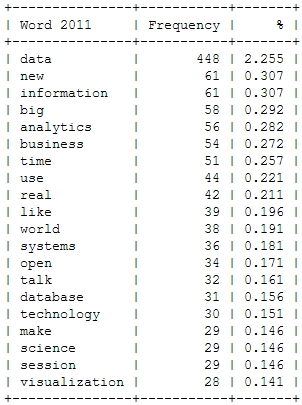
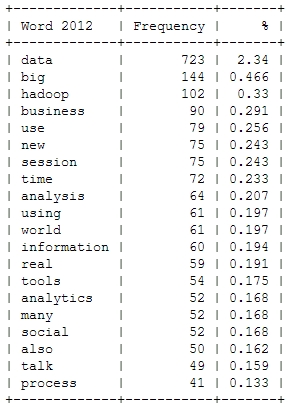
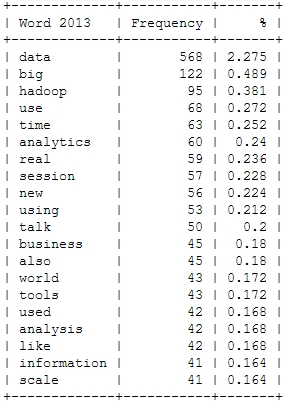
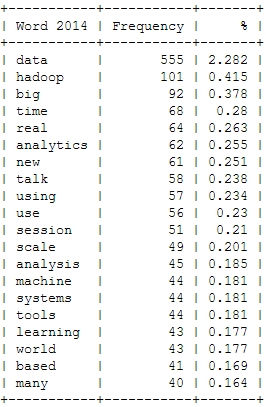
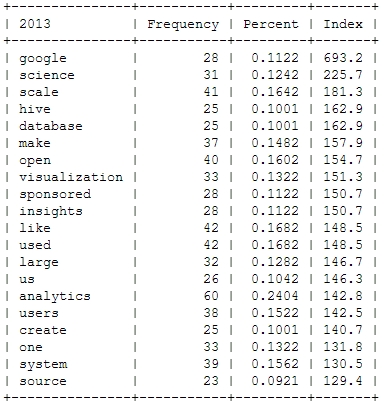
Here’s a look at the resulting insights. First, I analyzed the most frequent words, people used in their abstracts (after excluding common English language stop words). As a starter, here’s the Top 20 words for the last four Strata conferences:
This is just to check, whether all the important buzzwords are there and we’re measuring the right things here: Data – check! Hadoop – check! Big – check! Business – check! Already with this simple frequency count, one thing seems very interesting: Hadoop didn’t seem to be a big topic in the community until 2012. Another random conclusion could be that 2011 was the year where Big Data really was “new”. This word loses traction in the following years.
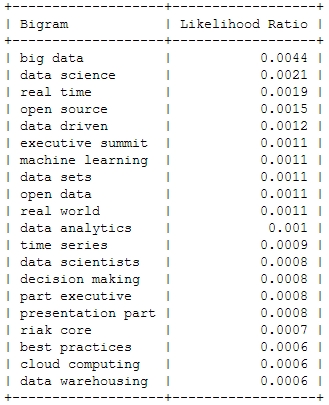
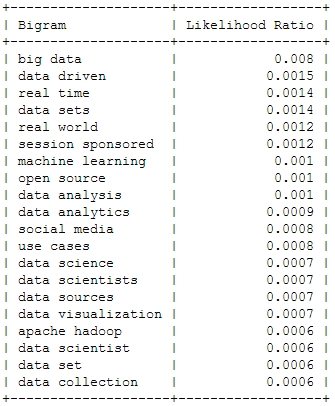
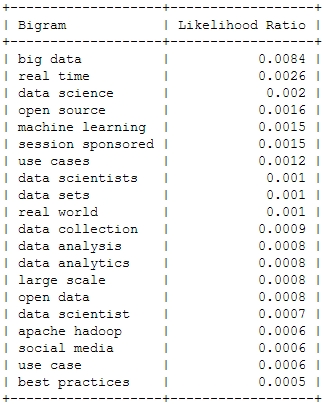
And now for something a bit more sophisticated: Bigrams or frequently used word combinations:
2011
2012
2013
2014
Of course, the top bigram through all the years is “big data”, which is not entirely unexpected. But you can clearly see some variation among the Top 20. Looking at the relative frequency of the mentions, you can see that the most important topic “Big Data” will probably not be as important in this years conference – the topical variety seems to be increasing:
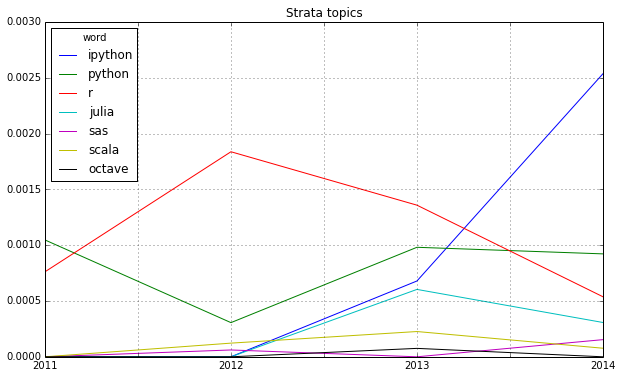
Looking at some famous programming and mathematical languages, the strong dominance of R seems to be broken by Python or IPython (and its Notebook environment) which seems to have established itself as the ideal programming tool for the nerdy real-time presentation of data hacks. \o/
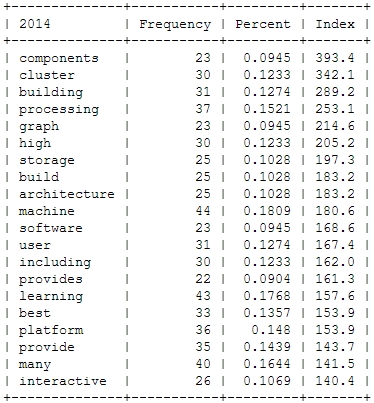
Another trend can be seen in the following chart: Big Data seems to become more and more faceted over the years. The dominant focus on business applications of data analysis seems to be over and the number of different topics discussed on the conference seems to be increasing:
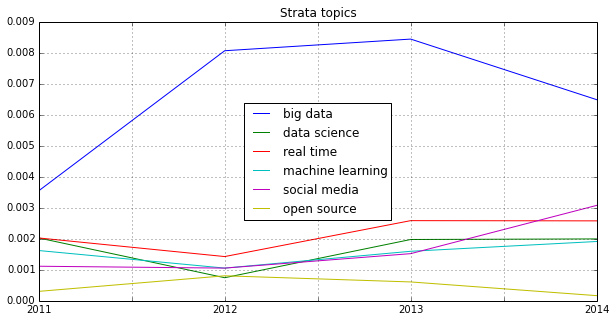
Finally, let’s take a more systematic look at rising topics at Strata Conferences. To find out which topics were gaining momentum, I calculated the relative frequencies of all the words and compared them to the year before. So, here’s the trending topics:
These charts show that 2012 was indeed the “Hadoop-Strata” where this technology was the great story for the community, but also the programming language R became the favorite Swiss knife for data scientists. 2013 was about applications like Hive that run on top of Hadoop, data visualizations and Google seemed to generate a lot of buzz in the community. Also, 2013 was the year, data really became a science – this is the second most important trending topic. And this was exactly the way, I experienced the 2013 Strata “on the ground” in Santa Clara.
What will 2014 bring? The data suggests, it will be the return of the hardware (e.g. high performance clusters), but also about building data architectures, bringing data know-how into organizations and on a more technical dimension about graph processing. Sounds very promising in my ears!
A lot of people still have a lot of respect for Hadoop and MapReduce. I experience it regularly in workshops with market researchers and advertising people. Hadoop’s image is quite comparable with Linux’ perceived image in the 1990s: a tool for professional users that requires a lot of configuration. But in the same way, there were some user-friendly distributions (e.g. Suse), there are MapReduce tools that require almost no configuration.
One favorite example is the ease and speed, you can do serious analytical work on the Google n-grams corpus with Hive on Amazon’s Elastic MapReduce platform. I adapted the very helpful code from the AWS tutorial on the English corpus to find out the trending German words (or 1-grams) for the last century. You need to have an Amazon AWS account and valid SSH keys to connect to the machines you are running the MapReduce programs on (here’s the whole hive query file).
Start your Elastic MapReduce cluster on the EMR console. I used 1 Master and 19 slave nodes. Select your AWS ssh authorization key. Remember: from this moment on, your cluster is generating costs. So, don’t forget to terminate the cluster after the job is done!
If your Cluster has been set-up and is running, note the Master-Node-DNS. Open a SSH client (e.g. Putty on Windows or ssh on Linux) and connect to the master node with the ssh key. Your username on the remote machine is “hadoop”.
Start “hive” and set some useful defaults for the analytical job:
set hive.base.inputformat=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set mapred.min.split.size=134217728;
The first code snippet connects to the 1-gram dataset which resides on the S3 storage:
CREATE EXTERNAL TABLE german_1grams (
gram string,
year int,
occurrences bigint,
pages bigint,
books bigint
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS SEQUENCEFILE
LOCATION 's3://datasets.elasticmapreduce/ngrams/books/20090715/ger-all/1gram/';
Now, we can use this database to perform some operations. The first step is to normalize the database, e.g. to transform all words to lower case and remove 1-grams that are no proper words. Of course you could further refine this step to remove stopwords or reduce the words to their stems by stemming or lemmatization.
CREATE TABLE normalized (
gram string,
year int,
occurrences bigint
);
And then we populate this table:
INSERT OVERWRITE TABLE normalized
SELECT
lower(gram),
year,
occurrences
FROM
german_1grams
WHERE
year >= 1889 AND
gram REGEXP "^[A-Za-z+'-]+$";
The previous steps should run quite fast. Here’s the step that really need to be run on a multi-machine cluster:
CREATE TABLE by_decade (
gram string,
decade int,
ratio double
);
INSERT OVERWRITE TABLE by_decade
SELECT
a.gram,
b.decade,
sum(a.occurrences) / b.total
FROM
normalized a
JOIN (
SELECT
substr(year, 0, 3) as decade,
sum(occurrences) as total
FROM
normalized
GROUP BY
substr(year, 0, 3)
) b
ON
substr(a.year, 0, 3) = b.decade
GROUP BY
a.gram,
b.decade,
b.total;
The final step is to count all the trending words and export the data:
CREATE TABLE result_decade (
gram string,
decade int,
ratio double,
increase double );
INSERT OVERWRITE TABLE result_decade
SELECT
a.gram as gram,
a.decade as decade,
a.ratio as ratio,
a.ratio / b.ratio as increase
FROM
by_decade a
JOIN
by_decade b
ON
a.gram = b.gram and
a.decade - 1 = b.decade
WHERE
a.ratio > 0.000001 and
a.decade >= 190
DISTRIBUTE BY
decade
SORT BY
decade ASC,
increase DESC;
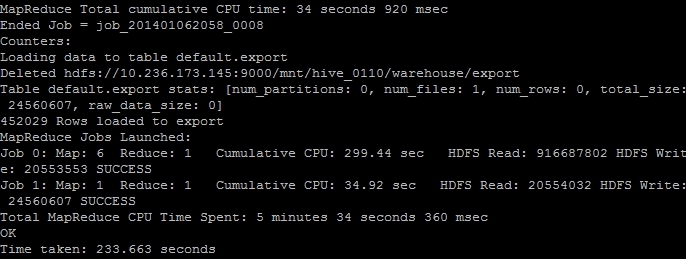
The result is saved as a tab delimited plaintext data file. We just have to find out its correct location and then transfer it from the Hadoop HDFS file system to the “normal” file system on the remote machine and then transfer it to our local computer. The (successful) end of the hive job should look like this on your ssh console:
The line “Deleted hdfs://x.x.x.x:9000/mnt/hive_0110/warehouse/export” gives you the information where the file is located. You can transfer it with the following command:
$ hdfs dfs -cat /mnt/hive_0110/warehouse/export/* > ~/export_file.txt
Now the data is in the home directory of the remote hadoop user in the file export_file.txt. With a secure file copy program such as scp or WinSCP you can download the file to your local machine. On a Linux machine, I should have converted the AWS SSH key in the Linux format (id_rsa and id_rsa.pub) and then added. With the following command I could download our results (replace x.x.x.x with your IP address or the Master-Host-DNS):
$ scp your_username@x.x.x.x:export_file.txt ~/export_file.txt
After you verified that the file is intact, you can terminate your Elastic MapReduce instances.
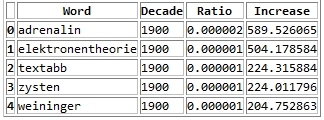
As a result you get a large text file with information on the ngram, decade, relative frequency and growth ratio in comparison with the previous decade. After converting this file into a more readable Excel document with this Python program, it looks like this:
Values higher than 1 in the increase column means that this word has grown in importance while values lower than 1 means that this word had been used more frequently in the previous decade.
Just a few months after Ogilvy & Mather created a new job position for a Chief Data Officer Todd Cullen, another WPP agency is following this example. Mindshare USA just appointed Bob Ivins as the company’s first Chief Data Officer directly reporting to the CEO Colin Kinsella.
Among the reasons for this move seems to be the growing importance of passively collected data in the agencies’ data warehouses and their clients’ marketing and enterprise software. Then there’s of course the massive data wealth that’s out there in the open: billions of tweets, check-ins, posts and comments by the modern digital population.
Now that data management platforms such as x+1, BlueKai or Adobe are among the standard tools in digital marketing and audience-buying – and the larger agencies even work with their own custom-created platforms – all in all data is becoming the new competitive edge.
This development gains further traction with a new development: Up to now, agencies were the only ones with full access to advertising data. They were the ones who did the ROI modelings and attribution analyses – and charged their clients for this service. But more and more advertisers are demanding their campaign data back in order to do their own analyses in combination with market and media surveys, customer data and retail data.
Agencies suddenly are in need to develop new offers for their clients that mean more than just evaluating media plans and campaign KPIs. Especially since the advent of real-time bidding and automated optimization, media planning has lost quite lot of importance for the agencies. I’d argue one of their new business fields will be data-driven:
identification of data-sources and data brokerage
analysis of their customers’ data-value
combination and refinement of data
real-time data management and data-driven learning
This all hints at a bright future for Data Scientists and Data Officers in advertising.



 2014 was a great year in data science – and also an exciting year for me personally from a very inspirational
2014 was a great year in data science – and also an exciting year for me personally from a very inspirational 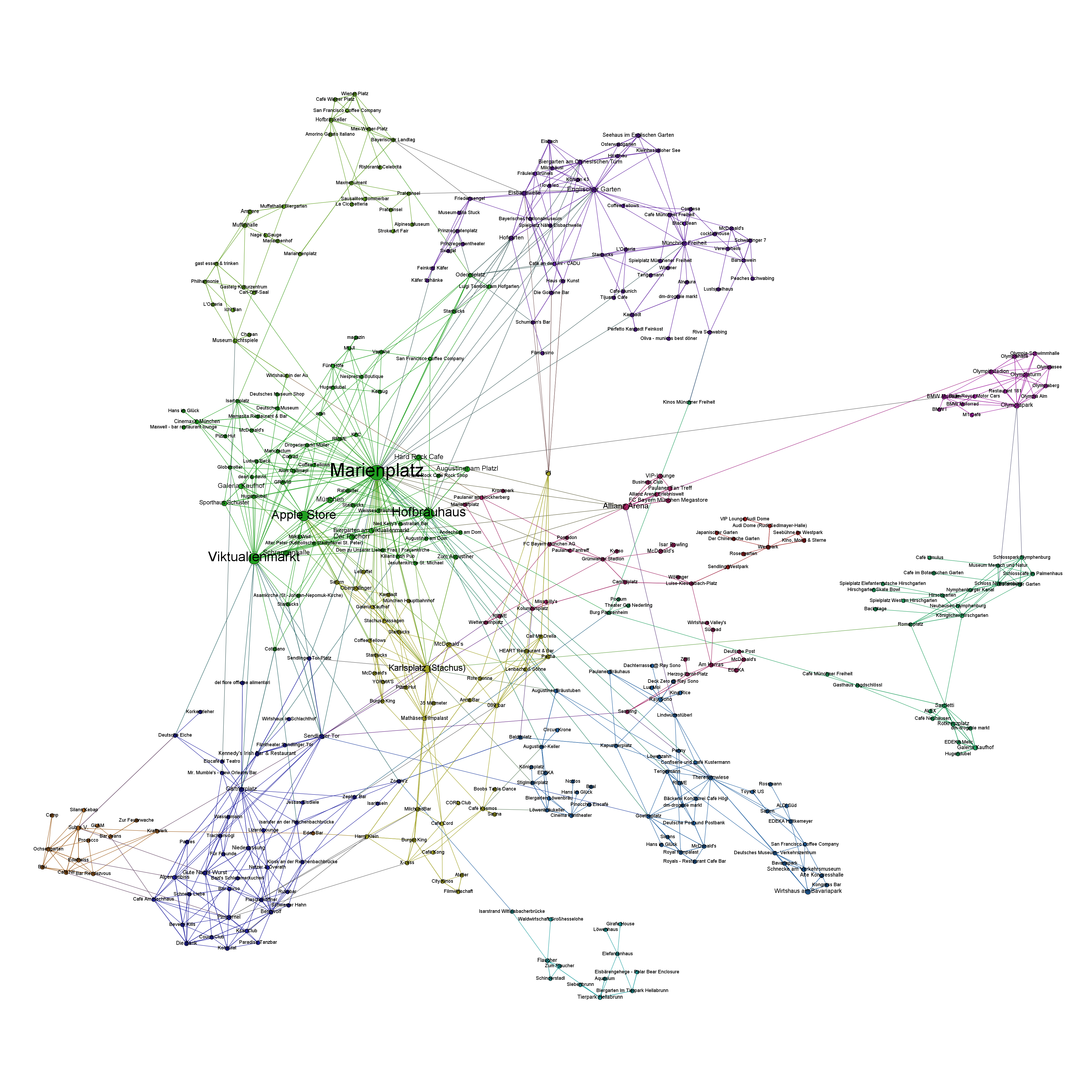















{kind=link}
{kind=link}