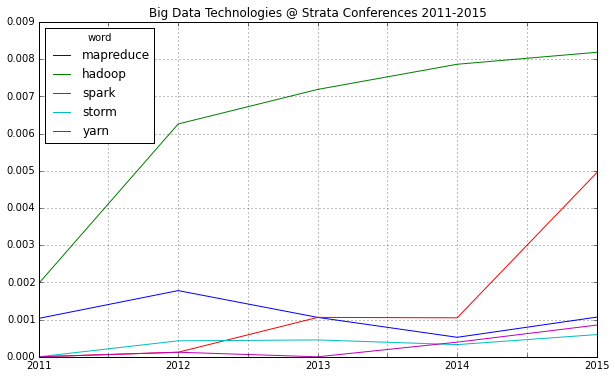
In one week, the 2015 edition of Strata Conference (or rather: Strata + Hadoop World) will open its doors to data scientists and big data practitioners from all over the world. What will be the most important big data technology trends for this year? As last year, I ran an analysis on the Strata abstract for 2015 and compared them to the previous years.
One thing immediately strikes: 2015 will be probably known as the “Spark Strata”:
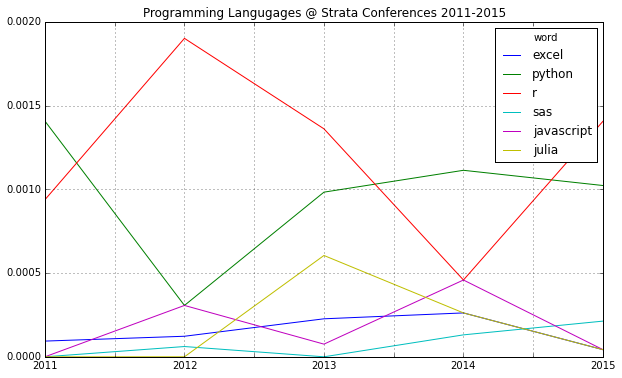
If you compare mentions of the major programming languages in data science, there’s another interesting find: R seems to have a comeback and Python may be losing some of its momentum:
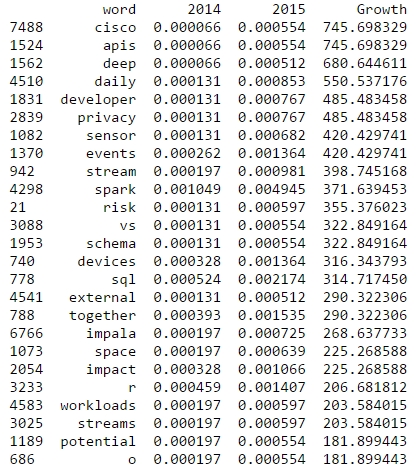
R is also among the rising topics if you look at the word frequencies for 2015 and 2014:
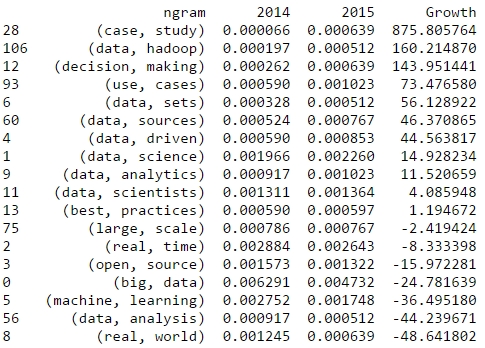
Now, let’s take a look at bigrams that have been gaining a lot of traction since the last Strata conference. From the following table, we could expect a lot more case studies than in the previous years:
This analysis has been done with IPython and Pandas. See the approach in this notebook.
Looking forward to meeting you all at Strata Conference next week! I’ll be around all three days and always in for a chat on data science.
Abstract: Data is the new media. Thus the postulates of our Slow Media Manifesto should be applicable on Big Data, too. Slow Data in this sense is meaningful data, relevant for society, driving creativity and scientific thinking. Slow Data is beautiful data.
From Slow Media to Slow Data
Five years ago we wrote the Slow Media Manifesto. We were concerned about the strange dichotomy by which people separated old media from new media to make their point about quality, ethics, and aesthetics. With Big Data, I now encounter a similar mindset. Just like people were scoffing social media to be just doodles, scribbling, or worse, I now see people scornfully raising their eyebrows about the lack of structure, missing consistency, and other alleged flaws they imagine Big Data to carry. As if “good old data” with a small sample size, representativeness, and other formalistic criteria would be a better thing as such. Again what these people see is just an evil new vice swamped over their mature businesses by unseasoned startups however, insanely well funded. I have gone through this argument twice already. It was wrong in the 90s when the web started, it was wrong again in the 2000s regarding social media, and it will not become right this time. Because it is not the technology paradigm that makes quality.
A mathematician, like a painter or a poet, is a maker of patterns. If his patterns are more permanent than theirs, it is because they are made with ideas. Beauty is the first test: there is no permanent place in the world for ugly mathematics.
Godfrey Harold Hardy
Data is the new media. I have written about this, too. The traditional concept of media becomes more and more directly intertwined with data, with data storytelling, data journalism, and their likes, indirectly because search, targeted advertising, content filtering, and other predictive technologies increasingly influence what we will find presented as media content.
Therefore I think it makes sense to take Slow Media and ask about Slow Data, too.
Highly curated small data
For what is useful above all is technique.
Godfrey Harold Hardy
Direct marketing data sets tend to be not very high quality (sorry CRM folks, but I know what I am talking about). Many records are only partly qualified, if at all. Moreover, the information on which the targeting is based is often outdated.
Small samples can enhance large heaps of data
In 2006 I oversaw a major market survey, the Typologie der Wünsche. This very expensive market research was conducted diligently according to the rules of the trade of social science. The questionnaire went through the toughest lectorship before it would be considered ready to be send out to the interviewers. The survey was done face to face, based on a cautiously drawn sample of 10.000 people per year. The results underwent permanent quality assurance. To be sure about the quality of the survey it was conducted by three independent research agencies. By doing this we could cross check plausibility.
Since my employer was also involved in direct marketing with a huge database of addresses, call centers, and logistics, we developed a method to use the highly curated market survey with its rather small sample to calibrate and enhance the “dirty” records of the CRM business. This was working so well that we started a cooperation with Deutsche Post to do the same, but on a much larger scale. Our small but precious data was matched with all 40 million addresses in Germany.
When working for MediaCom I was involved with a similar project. Television ratings are measured by expensive panels in most markets, usually run and funded by joint industry committees like BARB in the UK or AGF in Germany. Of course such a panel is restricted to just a few thousand households. Since in traditional broadcasting there are only some ten relevant TV channels in any market, this panel size is sufficient to support media planning. But internet usage is so much more fragmented that a panel of that sort would hardly make sense. So we took the data that we had collected via web tracking – again some 40 million records. We again found a way to infuse the TV panel data into the online data and could by that calculate the probabilities that the owner of a certain cookie would have had contact with a certain advertising campaign on TV or not. And again a small but highly curated and very specialized data set was used to greatly increase the value of the larger Big Data set.
Bringing scientific knowledge into Big Data
Archimedes will be remembered when Aeschylus is forgotten, because languages die and mathematical ideas do not.
Godfrey Harold Hardy
Another example where small but highly curated data is crucial for data science are data sets that contain scientific information which otherwise is not inherent in the data. Text mining works best when you can use quantitative methods without thinking about those difficult cultural concepts like ‘meaning’ or ‘semantics’. Detection of relevant content with ngram ranking, or text comparison based on cosine vector distance are the most powerful tools to analyze texts even in unfamiliar languages or alphabets. However, all the quantitative text mining procedures require the text to be preprocessed: All vocabulary with only grammatical function that would not add to the meaning has to be stripped off first. It is also useful to bring the words to their root form (picture verbs into infinitive, nouns into nominative singular). This indispensable work is done with special corpora, dictionaries, or better call it libraries, that contain all the required information. These corpora are handmade by linguists. Packages like Python’s NLTK have them incorporated in a handy way.
I am interested in mathematics only as a creative art.
Godfrey Harold Hardy
“Beautiful evidence” is what Edward Tufte calls good visualization. Information can truly be brought to us in a beautiful way. Data visualization as an art form had also entered the Sanctum of high arts when the group Asymptote was presented at Documenta 11 in 2002. Visual storytelling today has transformed. What used to be cartoons or engravings like this one here to illustrate the text, is now infographics that are the story.
Generative art is another data-driven art format. When I was an undergraduate The Fractal Geometry of Nature had finally tickled down to the math classes. With my Atari Mega ST I devoured all fractal code snippets I could get into my hands. What fascinated me most were not the (usually rather kitschy) colorful fractal images. I wanted to have fractal music, generative music that would evolve algorithmically from my code.
Although fractals as an art-thing where certainly more a fad, not well suited to turn into real art, generative art as such has since then become a strong branch in the Arts. Much of today’s music relies heavily on algorithmic patterns in many of its dimensions, from rhythm to tune, to overtone spectra. Also in video art, algorithmically rendered images are ubiquitous.
Art from data will further evolve. I trust we will see data fiction become a genre of its own.
Data as critique
… there is no scorn more profound, or on the whole more justifiable, than that of the men who make for the men who explain. Exposition, criticism, appreciation, is work for second-rate minds.
Godfrey Harold Hardy
Critique is the way to think in the alternative. Critique means not to trust what is sold to you as truth. Data is always ambiguous. Meaning is imposed upon data by interpretation. Critique is to deconstruct interpretation, to give room for other ways to interpret. The other stories we may draw from our data do not have to be more plausible, at all. Often the absurd is what unveils hidden aspects of our models. As long as our alternative interpretations are at least possible, we should follow these routes to see where they end. Data fiction is the means to turn data into a tool of critique.
Data science has changed our perception of how lasting we take our results to be. In data science we usually do not see a conclusion as true or permanent. Rather we hope that a correlation or pattern that we observe will remain stable, at least for a while. There is no hypothesis that we would accept and then tick off just because our test statistics turned significant. We would always continue to a/b-test alternative models, that would substitute an earlier winner of the test-game. In data science, we maximize critical thinking by not even seeing what we do as falsification because we would not have thought of the previous state as true in the first place. Truth in data science means just the most plausible interpretation at a time; ephemeral.
Slow Data accordingly means to use data to deconstruct the obvious, as well as to built alternatives.
Ethical data
A science is said to be useful if its development tends to accentuate the existing inequalities in the distribution of wealth, or more directly promotes the destruction of human life.
Godfrey Harold Hardy
The two use cases that dominate the discussion about Big Data are the right opposite of ethical: Targeted advertising, and mass surveillance. As Bruce Sterling points out, both are in essence just two aspects of the same thing that he calls ‘surveillance marketing’. I feel sad that this is what seams to be the prominent use of our work: To sell things to people who do not want them, and to keep people down.
However, I am confident that the benign uses of Big Data will soon offer such high incentive that we will awake from our military marketing nightmares. With open data we build a public space. All the most useful Big Data tools are all in the pubic domain anyway: Hadoop, Mesos, R, Python, Gephy, etc. etc.
Ethical data is data that makes a difference for society. Ethical data is relevant for people’s lives: To control traffic, to make agriculture more sustainable, to supply energy, to help plan cities and administer the states. This data will be crucial to facilitate our living together with ten billion people.
Slow Data is data that makes a difference for people’s lives.
Political data
It is never worth a first class man’s time to express a majority opinion. By definition, there are plenty of others to do that.
Godfrey Harold Hardy
“Code is Law” is the catch phrase of Lawrence Lessig famous bestseller on the future of democracy. From the beginning of the Internet revolution, there has been the discussion, whether our new forms of media and communication would lead to another revolution as well: a political one. Many of the media and platforms that rose over last decade show aspects of communal or even social systems – and hence might be called Social Media with good cause. It does not come as a surprise that we start to see the development of the communication platforms that are genuinely meant to support and at the same time to experiment with new forms of political participation, like Proxy-Voting or Liquid Democracy, which had been hardly conceivable without the infrastructure of the Web. Since these new forms of presenting, debating, and voting for policies have been started occurring just recently we can expect that many other varieties will appear, new concepts to translate the internet paradigm into social decision making. Nevertheless, how do these new forms of voting work? Are they really mapping the volonté generale into decisions? If so, will it work in a sustainable, stable, continuous way? And how to evaluate the systems, one compared to another? I currently work in a scientific research project on how to deal with these questions. Today I am not yet ready to present conclusions. Nonetheless, I already see that using data for quantitative simulation is a good approach to approximate the complex dynamics of future data-driven political decision-making.
Politics as defined by Aristotle means to have the freedom to make decisions based on ethics and beliefs and not driven by necessities, the latter is what he calls economics. To deal with law in this sense is similar to my text mining example above. If law is codified, it can be executed syntactically, indeed quite similar to a computer program. But to define what is just, what should be put into the laws, is not syntactical, at all. Ideally this would be exclusively political. I don’t think, algorithmic legislation would be desirable, I doubt that it would be even feasible.
Slow Data means to use data to explore new forms of political participation without rush.
Machine thinking
Chess problems are the hymn-tunes of mathematics.
Godfrey Harold Hardy
‘Could a machine think?’ is the core question of AI. The way we think about answering this question immediately lead us beyond computer science: What does it mean to think? What is consciousness? Since the 1980s there has been a fascinating exchange of arguments about the possibility of artificial intelligence, culminating in the Chinese Room debate between John Searle and the Churchlands. Searle and in an even more abstract way, David Chalmers made good points why a simulation of consciousness that would even pass the Turing test, would never become really conscious. Their counterparts, most prominent Douglas Hofstadter, would reject Chalmers neo-Kantianism as metaphysics.
Google has recently published an interesting paper on artificial visual intelligence. They trained mathematical models with random pictures from social media sites. And – surprise! – their algorithm came up with a concept of “What is a cat?”. The point is, nobody had told the algorithm to look for cat-like patterns. Are we witnessing the birth of artificial intelligence here? On the one hand, Google’s algorithm seams to do exactly what Hofstadter predicted. It is adaptive to environmental influences and translates the sensory inputs into something that we interpret as meaning. On the other side was the training sample far from random. The pictures were what people had pictured. It was a collaboratively curated set of rather small variety. The pattern the algorithm found was in fact imposed by “classic” consciousnesses, by the minds of “real” people.
Slow Data is the essence that makes our algorithm intelligent.
The beauty of scientific data
Beauty is the first test: there is no permanent place in this world for ugly mathematics.
Godfrey Harold Hardy
Now returning to Hardy’s quote from the beginning, when I was studying mathematics I was puzzled by the strange aestheticism that many mathematicians would force upon their train of thoughts. Times have changed since then. Today we have many theorems solved that were considered hard problems. Computational proofing has taken its role in mathematical epistemology. Proofs filling thousands of pages are not uncommon.
Science, physics in particular, is driven by accurate data. Kepler could dismiss the simple heliocentric model because Tycho Brahe had measured the movements of the planets to such accuracy that the model of circular orbits could no longer be maintained. Edwin Hubble discovered the structure of our expanding universe because Milton Humason and other astronomers at Mt. Wilson had provided for spectroscopic images of thousands of galaxies, exact enough to derive Hubble’s constant from the redshift of the prominent Fraunhofer lines. Einstein’s Special Theory of Relativity relies on the data of Michelson and Morley who had shown that light would travel at constant speed, no matter the angle to the direction of our earth’s travel around the sun it was measured against. Such uncompromisingly accurate data, collected in a painstaking struggle without any guarantee to pay off – this is what really brought the great breakthroughs in science.
Finally, while mathematics is turning partially into syntax, the core of physics at the same time unfolds in the strange blossoms of the most beautiful mathematics imaginable. In the intersect of cosmology, dealing with the very largest objective imaginable – the entirety of the cosmos, and quantum physics on the smallest scale lies the alien world of black holes, string theory, and quantum gravity. The scale of these phenomena, the fabric of space-time is likely defined by relating Planck’s constant to Newton’s constant and the speed of light is so unimaginably small – some 40 powers of magnitude smaller than the size of an electron – that we can’t expect to measure any data even near to it any time soon. We can only rely on our logic, our sense for mathematical harmony, and the creative mind.
Slow Data
Slow Data – for me the space of beautiful data is spanned by these aspects. I am confident that we do not need an update to our manifesto. However, I hope that we will see many examples of valuable data, of data that helps people, that creates experiences unseen, and that opens the doors to new worlds of our knowledge and imagination.
Appendix: Slow Media
The Slow Media movement was kicked off with the Slow Media Manifesto that Sabria David, Benedikt Koehler and I had written on new year’s day 2010. Immediately after we had published the manifesto, it was translated into Russian, French, and some other 20 languages.

{kind=link}