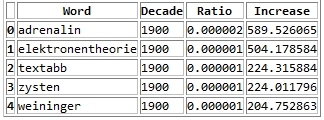
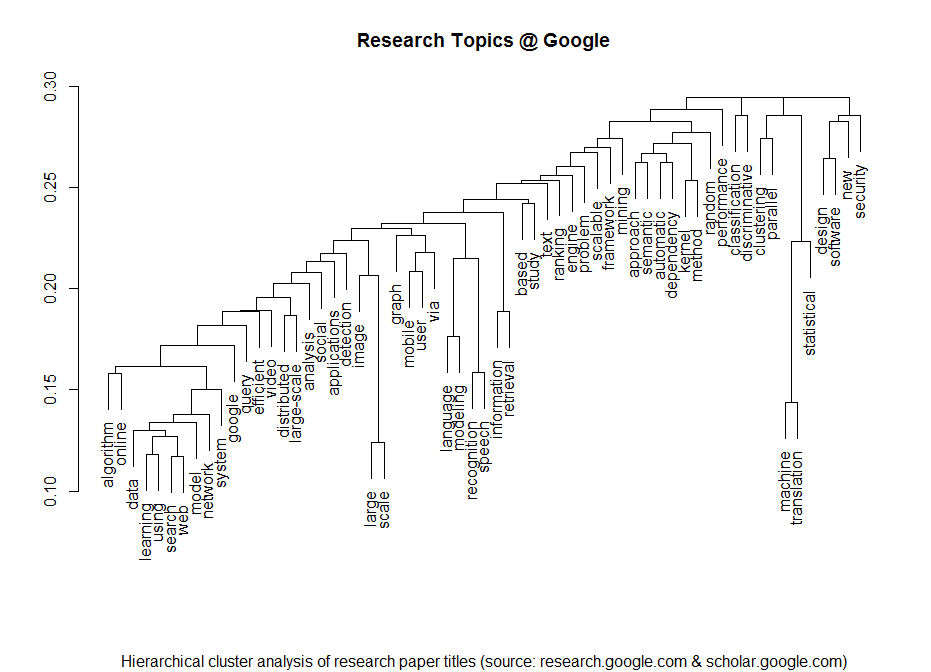
One of the most exciting applications of Social Media data is the automated identification, evaluation and prediction of trends. I already sketched some ideas in this blog post. Last year – and this was one of my personal highlights – I had the opportunity to speak at the PyData 2014 Berlin on the topic of Street Fighting Trend Research.
In my talk I presented some more general thoughts on trend research (or “coolhunting” as it is called nowadays) on the Internet. But at the core were three examples on how to identify research trends from the web (see this blogpost), how to mine conference proposals (see this analysis of Strata abstracts) and how to identify trending locations on Foursquare (see here). All three examples are also available as IPython Notebooks on my Github page. And here’s the recorded version of the talk.
The PyData conference was one of the best conferences I attended. Not only were the topics very diverse – ranging from GPU optimization to the representation of women in the PyData community – but also the people attending the conference were coming from different backgrounds: lawyers, engineers, physicists, computer scientists (of course) or statisticians. But still, with every talk and every conversation in the hallways, you could feel the wild euphoria connecting us all with the programming language and the incredible curiosity.
 2014 was a great year in data science – and also an exciting year for me personally from a very inspirational
2014 was a great year in data science – and also an exciting year for me personally from a very inspirational