(This is the transcript of a key-note speech by Benedikt and Joerg 2010 on the Tag der Marktforschung, the summit of the German Market Researchers’ Professional Association BVM – [1])
Market research as an offspring of industrial society is legitimized by the Grand Narrative of modernism. But this narrative does no longer describe reality in the 21st century – and particularly not for market research. The theatre of market research has left the Euclidian space of modernism and has moved on into the databases, networks and social communities. It is time for institutionalized market research to strike tents and follow reality.
“Official culture still strives to force the new media to do the work of the old media. But the horseless carriage did not do the work of the horse; it abolished the horse and did what the horse could never do.” H. Marshall McLuhan
1. Universally available knowledge
In facing the unimaginable abundance of structured information available anytime and everywhere via the Internet, the idea of genuine knowledge progress appears naïve. When literally the whole knowledge of the world is only one click away, research tends to become database search, meta analysis, aggregating existing research or data mining, i.e. algorithm-based analysis of large datasets.
2. Perpetual beta
What can be found in Wikipedia today is not necessarily the same that could be found a few weeks ago. Knowledge is in permanent flow. But this opposes the classic procedure in market research: raising a question, starting fieldwork, finding answers and finally publishing a paper or report. In software development, final versions have been long given way to releasing versions; what gets published is still a beta version, an intermediate result that gets completed and perfected in the process of being used. Market research will have to publish its studies likewise to be further evolving while being used.
3. Users replacing institutes
The ideal market researcher of yore, like an ethnologist, would enter the strange world of the consumers and would come back with plenty of information that could be spread like a treasure in front of the employer. Preconditions had been large panels, expensive technologies, and enormous amount of special knowledge. Only institutes were able to conduct the costly research. Today, however “common” Internet users can conduct online surveys with the usual number of observed cases.
4. Companies losing their clear boundaries
“Force and violence are justified in this [oiconomic] sphere because they are the only means to master necessity.” Hannah Arendt
In her main opus “The Human Condition” Hannah Arendt describes the Oikos, the realm of economy, as the place where the struggle for life takes place, where no moral is known, except survival. The Polis in opposition to this represents the principle of purposeless cohabitation in dignity: the public space where the Oikos with its necessities has no business.
When large corporations become relevant if not the only effective communication channels, they tend to take the role of public infrastructure. At the same time, by being responsible only to their shareholders, they withdraw from social or ethical discussions. As a result, their decisions could hardly be based on ethic principles. With research ethics, the crucial question is: Can our traditional ways of democratic control, based on values that we regard important, still be asserted – and if not, how we could change this.
5. From target groups to communities
The traditional concept of target groups implies that there are criteria, objective and externally observable, which map observed human behavior sufficiently plausible to future behavior or other behavioral observations. Psychological motives however are largely not interesting.
Contemporary styles of living are strongly aligning, making the people appear increasingly similar one to each other (a worker, a craftsman or a teacher all buy their furniture at the same large retailer); however, with the Internet there are more possibilities than ever to find like-minded people even for most remote niche interests.
Often these new communities are regarded as substitute for target groups. But communities are something completely different from target groups, characterized by their members sharing something real and subjective in common: be it common interest or common fate. Thus, objective criteria also become questionable in market research.
6. The end of the survey
Google, Facebook and similar platforms collect incredible bulks of data. By growth of magnitudes quantity reverts to quality: they don’t just become bigger, but become completely new kinds of objects (e.g. petabyte memory and teraflop databases).
Seen from the users’ perspective Google is a useful search engine. From a different perspective, Google is a database of desire, meaning, context, human ideas and concepts. Given these databases, data collection is no longer the problem: rather to get the meaning behind the numbers.
7. Correlations are the new causalities
“Effects are perceived, whereas causes are conceived. Effects always precede causes in the actual development order.” H. Marshall McLuhan
In marketing it is often not important if there is really some causality to be conceived. Some correlation suffices to imply a certain probability. When performance marketing watches how people get from one website to the other, without being able to explain why: then it is good enough to know, that it is just the case.
8. The end of models
“Only for the dilettante, man and job match.” Egon Friedell
There is, as sketched before, an option for market research without theory. To take profit from new data sources and tools, the future market researcher has to act like a hacker, utilizing interfaces, data and IT-infrastructures in a creative way to achieve something that was not originally intended by this technology. The era of the professional expert is over.
9. Objectivity is only a nostalgic remembrance
Objectivity is a historical construct, formed in the 19th century and being kept in the constellation of mass society, mass market and mass media for a remarkably long time. With social networks in the Internet you do not encounter objects or specimens, but human beings that are able to self-confidently answer the gaze.
10. We need new research ethics
The category of the “consumer” shows the connection between aiming to explore our fellows and the wish to manipulate them. Reciprocity, the idea to give the researched population something back, has not been part of traditional market research’s view of the world.
In the Internet on the other hand, reciprocity and participation are expected. This has pivotal implications for our research ethics, if we want to secure the future cooperation of the women and men, which would not want to get mass-surveyed and mass-informed either. Likewise, some existing ethical concepts have become obsolete, such as the anonymity of the participants: who takes part in a project as a partner, does not need and not want to stay anonymous.
“Handle so, dass du die Menschheit sowohl in deiner Person, als in der Person eines jeden anderen jederzeit zugleich als Zweck, niemals bloß als Mittel brauchst.” Immanuel Kant






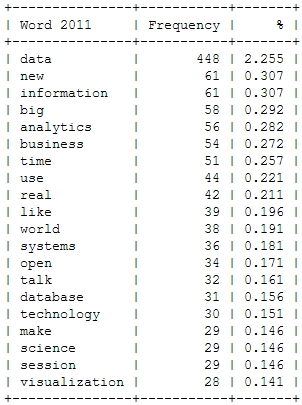
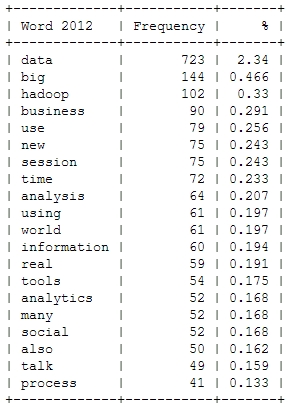
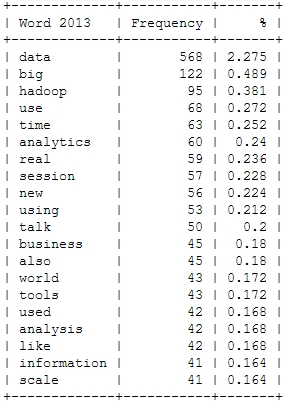
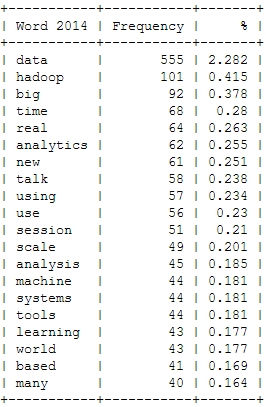
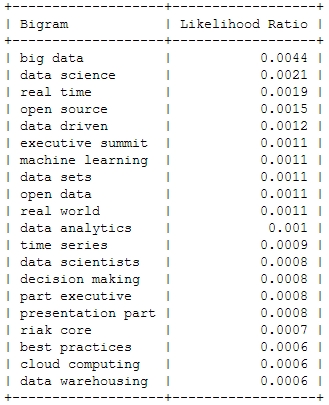
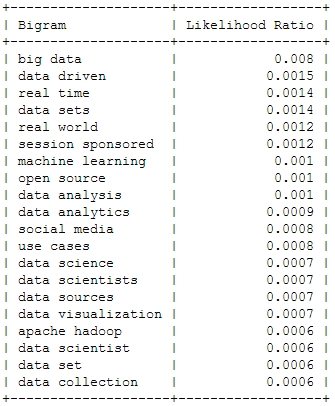
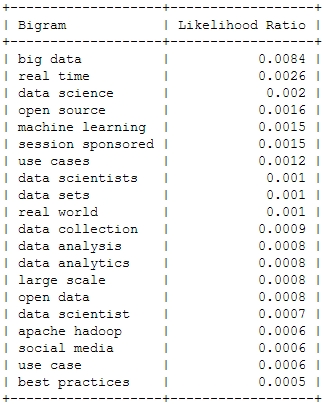

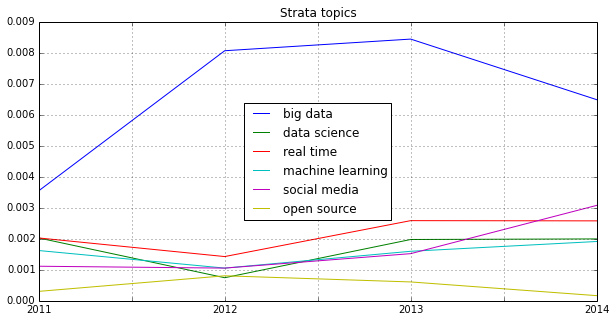





![[Wordcloud]](http://beautifuldata.net/wp-content/uploads/2013/05/wordcloud.png){kind=link}