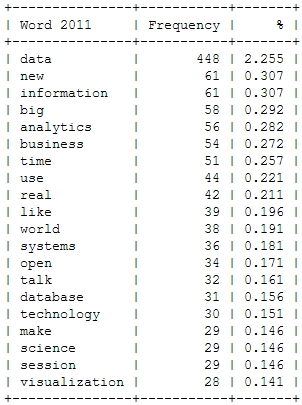
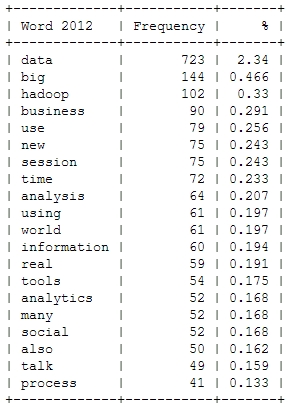
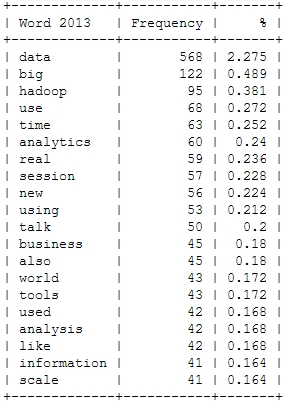
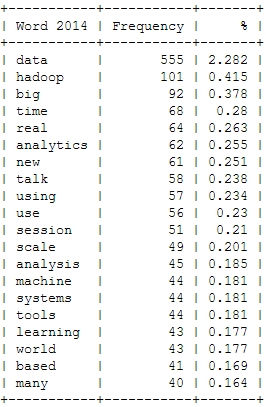
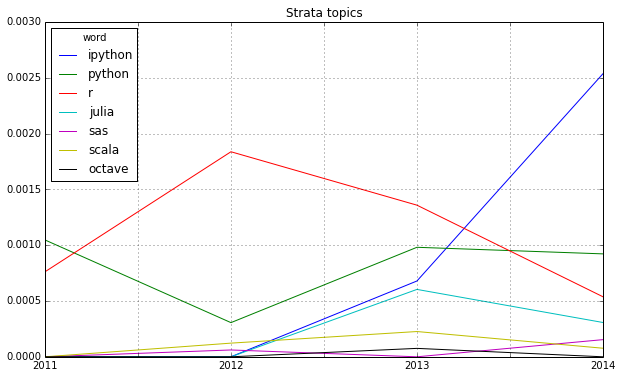
I already mentioned the Hastie & Tibshirani course on statistical learning as one of my personal highlights in data science last year. My second highlight is also an online course, also by leading experts on their field (this time: Big Data and data mining), also based on a (freely available) book and also by Stanford University professors: Jure Leskovec, Anand Rajamaran and Jeff Ullman’s course on “Mining Massive Datasets”.

If you’re interested in data science or data mining, chances are high that you have already been in touch with their book. It can safely be considered a standard work on the fascinating intersection of data mining algorithms, machine learning and Big Data. The 7 week course is the online version of the Stanford courses CS246 and the earlier version of CS345A.
 The course is very dense and covers a lot of territory from the book, for example:
The course is very dense and covers a lot of territory from the book, for example:
- How does Map Reduce work and why is it important?
- How can I retrieve frequently appearing combinations from very large sets of items such as shopping baskets?
- How to retain information about a datastream that does not fit in memory?
- What are the most common tasks in supervised machine learning and how to implement them?
- How do I program an intelligent system for recommending movies?
- How to compute optimal placements of online advertisements?
Some of the lectures are on a beginners to intermediate level, but some lectures cover very advanced topics. What I especially liked about this course is that a lot of the material covered really is state-of-the-art in data mining. Some algorithms – e.g. the BIGCLAM community detection and CUR matrix decomposition – had only been developed about year ago.
So, take a look at the book, and if you haven’t already: enroll at the Coursera course website to make sure you won’t miss the next session of this course.
 2014 was a great year in data science – and also an exciting year for me personally from a very inspirational
2014 was a great year in data science – and also an exciting year for me personally from a very inspirational