Once a year, the cosmopolitan digital avantgarde gathers in Munich to listen to keynotes on topics all the way from underground gardening to digital publishing at the DLD, hosted by Hubert Burda. In the last years, I did look at the event from a network analytical perspective. This year, I am analyzing the content, people were posting on Twitter in order to make comparisons to last years’ events and the most important trends right now.
To do this in the spirit of Street Fighting Trend Research, I limited myself to openly available free tools to do the analysis. The data-gathering part was done in the Google Drive platform with the help of Martin Hawksey’s wonderful TAGS script that is collecting all the tweets (or almost all) to a chosen hashtag or keyword such as “#DLD14” or “#DLD” in this case. Of course, there can be minor outages in the access to the search API, that appear as zero lines in the data – but that’s not different to data-collection e.g. in nanophysics and could be reframed as adding an extra challenge to the work of the data scientist 😉 The resulting timeline of Tweets during the 3 DLD days from Sunday to Tuesday looks like this:

You can clearly see three spikes for the conference days, the Monday spike being a bit higher than the first. Also, there is a slight decline during lunch time – so there doesn’t seem to be a lot food tweeting at the conference. To produce this chart (in IPython Notebook) I transformed the Twitter data to TimeSeries objects and carefully de-duplicated the data. In the next step, I time shifted the 2013 data to find out how the buzz levels differed between last years’ and this years’ event (unfortunately, I only have data for the first two days of DLD 2013.
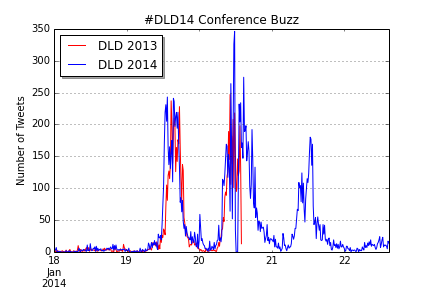
The similarity of the two curves is fascinating, isn’t it? Although there still are minor differences: DLD14 began somewhat earlier, had a small spike at midnight (the blogger meeting perhaps) and the second day was somewhat busier than at DLD13. But still, not only the relative, but also the absolute numbers were almost identical.
Now, let’s take a look at the devices used for sending Tweets from the event. Especially interesting is the relation between this years’ and last years’ percentages to see which devices are trending right now:
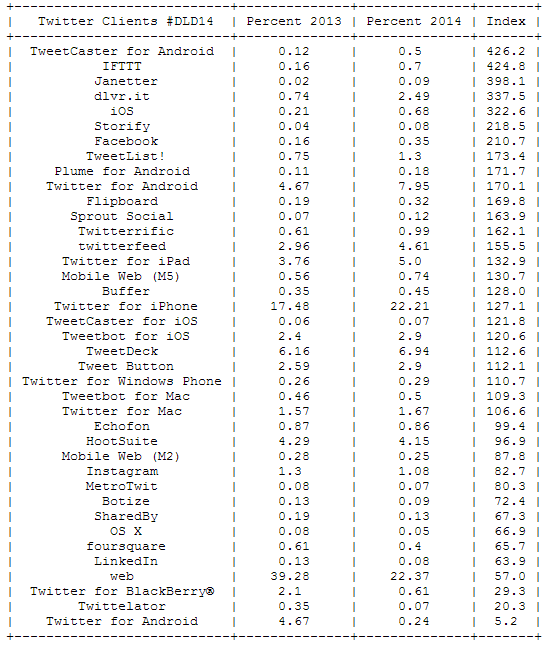
The message is clear: mobile clients are on the rise. Twitter for Android has almost doubled its share between 2013 and 2014, but Twitter for iPad and iPhone have also gained a lot of traction. The biggest losers is the regular Twitter web site dropping from 39 per cent of all Tweets to only 22 per cent.
The most important trending word is “DLD14”, but this is not surprising. But the other trending words allow deeper insights into the discussions at the DLD: This event was about a lot of money (Jimmy Wales billion dollar donation), Google, Munich and of course the mobile internet:

Compare this with the top words for DLD 2013:

Wait – “sex” among the 25 most important words at this conference? To find out what’s behind this story, I analyzed the most frequently used bigrams or word combinations in 2013 and 2014:
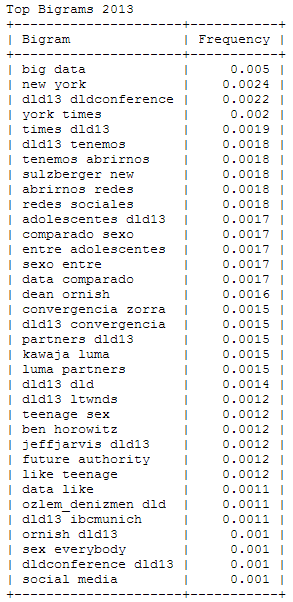

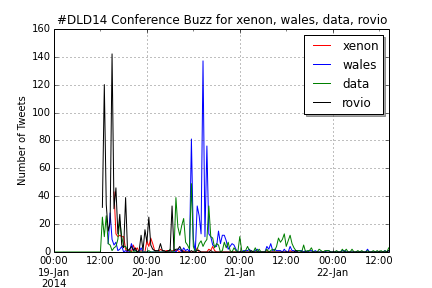
With a little background knowledge, it clearly shows that 2013’s “sex” is originating from a DJ Patil quote comparing “Big Data” (the no. 1 bigram) with “Teenage Sex”. You can also find this quotation appearing in Spanish fragments. Other bigrams that were defining the 2013 DLD were New York (Times) and (Arthur) Sulzberger, while in 2014 the buzz focused on Jimmy Wales, Rovio and the new Xenon processor and its implications for Moore’s law. In both years, a significant number of Tweets are written in Spanish language.
UPDATE: Here’s the IPython Notebook with all the code, this analysis has been based on.
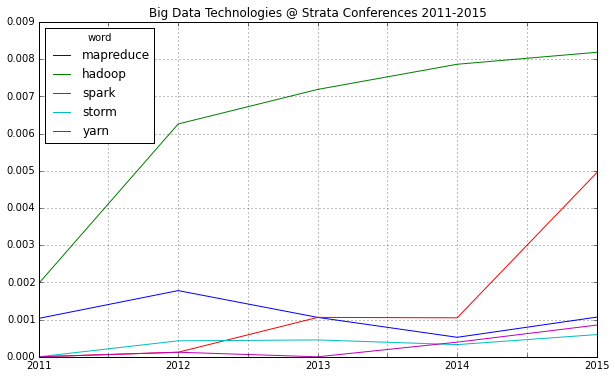
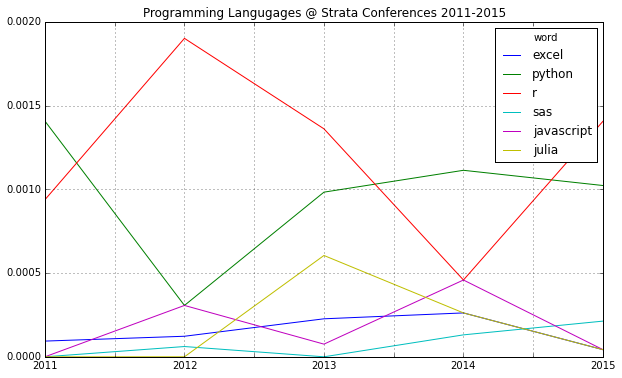
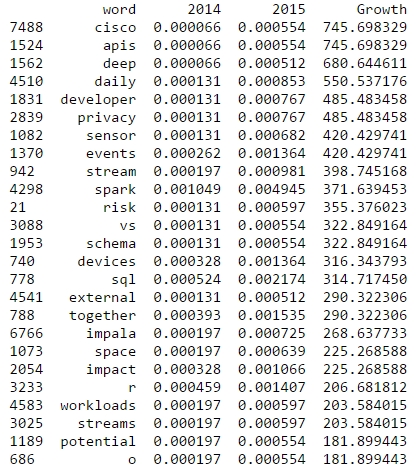
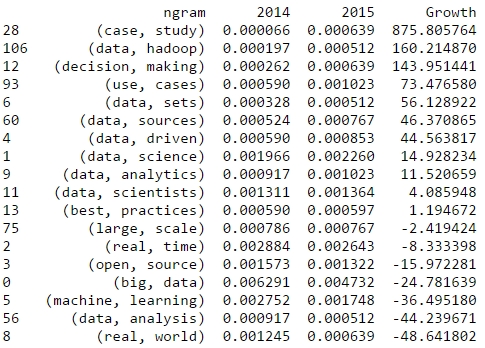

 2014 was a great year in data science – and also an exciting year for me personally from a very inspirational
2014 was a great year in data science – and also an exciting year for me personally from a very inspirational