One of the most interesting Big Data companies in this network analysis of Venture Capital connections has in my opinion been Domo. Not only did it receive clearly above average funding for such a young company, but it was also one of the nodes with the best connections through Venture Capital firms and their investments. It had one of the highest values for Betweenness Centrality, which means it connects a lot of the other nodes in the Big Data landscape.
Then, some days after I did the analysis and visualization, news broke that Domo received $125M from Greylock, Fidelity, Morgan Stanley and Salesforce among others. This is a great opportunity to see what this new financing round means in terms of network structure. Here’s Domo before the round:

And this is Domo $125M later. Notice how its huge Betweenness Centrality almost dwarfs the other nodes in the network. And through its new connections it is strongly connected to MongoDB:
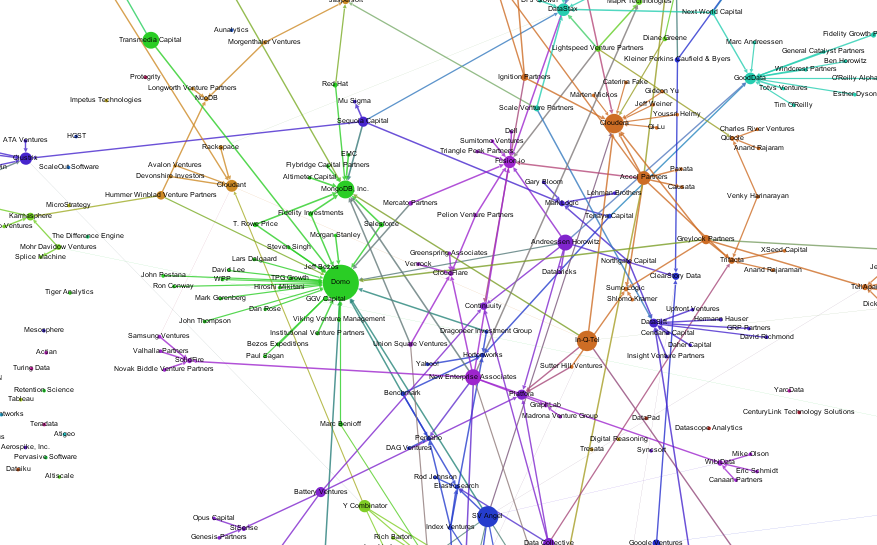
Here’s a look at the numbers, before Series C:
| Company | Centrality | |
|---|---|---|
| 1 | Domo | 0.1459 |
| 2 | Cloudera | 0.0890 |
| 3 | MemSQL | 0.0738 |
| 4 | The Climate Corporation | 0.0734 |
| 5 | Identified | 0.0696 |
| 6 | MongoDB, Inc. | 0.0673 |
| 7 | Greenplum Software | 0.0541 |
| 8 | CrowdFlower | 0.0501 |
| 9 | DataStax | 0.0489 |
| 10 | Fusion-io | 0.0488 |
And now:
| Company | Centrality | |
|---|---|---|
| 1 | Domo | 0.1655 |
| 2 | MemSQL | 0.0976 |
| 3 | Cloudera | 0.0797 |
| 4 | MongoDB, Inc. | 0.0722 |
| 5 | Identified | 0.0706 |
| 6 | The Climate Corporation | 0.0673 |
| 7 | Greenplum Software | 0.0535 |
| 8 | CrowdFlower | 0.0506 |
| 9 | DataStax | 0.0459 |
| 10 | Fusion-io | 0.0442 |
The new funding round now only increases Domo’s centrality but also MongoDB’s because of the shared investors Salesforce, T. Rowe Price and Fidelity Investments.




















{kind=link}
{kind=link}