One of the most interesting sources of social media data right now is the iPhone based image sharing platform Instagram. This social networking platform is based on images, which can be compared with Flickr, but with Instagram the global dimension is much more visible. And because of the seamless Twitter and Facebook integration, the networking component is stronger. And it has a great API 😉
The first thing that came to my mind when looking at the many options, the API is providing to developers, has been the tags. In the Instagram application, there is no separate field for tagging your (or other peoples’) images. Instead you would write it in the comment field as you would do in Twitter. But the API allows to fetch data by hashtags. After reading this fascinating article (and looking at the great images) in Monocle about the northern Chinese city of Harbin, I wanted to learn more about the visual representation of this city in Instagram.
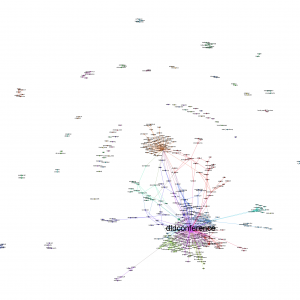
What I did was the following: I wrote a short Python program that fetched the 1.000 most recently posted images for any hashtag. As I could not get the two available Instagram Python modules to work properly, I wrote my own interface to Instagram based on pycurl. The data is then transformed into a network based on the co-occurence of hashtags for the images and saved in GraphML format with the Python module igraph. Other data (such as filters, users, locations etc.) that can be evaluated is saved in separate data sets. Here’s the network visualizations for China, Shanghai, Beijing, Hongkong, Shenzen and Harbin – not the whole network, but a reduced version only with the tags that were mentioned at least five times (click to enlarge):






I also calculated some interesting indicators for the six hashtags I explored:

The first thing to notice is that Harbin obviously is not as often being instagrammed as the Shanghai, Shenzhen, Hongkong or Beijing. An interesting indicator here is in the second data column: the daily number of images tagged with this location. Shenzhen seems to be the most active city with 3.4 images tagged “#shenzen”. Beijing is almost as active, while Shanghai is a bit behind. Finally, for Harbin, there’s not even one image every day. The unique tags is showing the diversity of hashtags used to describe images. Here, China is clearly in the lead. The next two indicators tell something about the connections between the tags: The density is calculated as the relation of actual to possible edges between the network nodes. Here, the smaller network of Harbin has the highest density and China and Shanghai the lowest. The average path length is a little below 2 for all hashtags.
Now, let’s take a look at the most frequently used hashtags:

What is interesting here: Harbin clearly does tell a story about snow, cold weather and a ice sculpture park, while Shanghai seems to be home for users frequently tagging themselves to advertise their instagramming skills (I marked the tags that refer to usernames with an asterisk). Most of the frequently used hashtags are Instagram lingo (instagood, instagram, ig, igers, instamood), refer to the equipment (iphonesia, iphoneography) or the region (china). Topical hashtags, that tell something about the city or the community can seldom be found in the top hashtags. Nonetheless, they are there. Here’s a selection of hashtags telling a story about the cities:

Finally, here is the most frequently liked image for each of the hashtags – to remind us that the numbers and networks only tell half the story. Enjoy and see if you can spot the ice sculptures in Harbin!
China:





Shanghai:





Beijing:





Hongkong:





Shenzhen:





Harbin:


























{kind=link}