Open foresight is a great way to look into future developments. Open data is the foundation to do this comprehensively and in a transparent way. As with most big data projects, the difficult part in open foresight is to collect the data and wrangle it to a form that can actually be processed. While in classic social research you’d have experimental measurements or field notes in a well defined format, dealing with open data is always a pain: not only is there no standard – the meaningful numbers might be found anywhere in your source and be called arbitrarily; also the context is not given by some structure that you’d have imposed into your data in advanced (as we used to do it in our hypothesis-driven set-ups).
In the last decade, crowdsourcing has proven to be a remedy to dealing with all kinds of challenges that are still to complex to be fully automatized, but which are not too hard to be worked out by humans. A nice example is zooniverse.org featuring many “citizen science projects”, from finding exoplanets or classifying galaxies, to helping to model global climate history by entering historic ships’ log data.
Climate change caused by humanity might be the best defended hypothesis in science; no other theory had do be defended against more money and effort to disprove it (except perhaps evolution, which has do fight a similar battle about ideology). But apart from the description, how climate will change and how that will effect local weather conditions, we might still be rather little aware of the consequences of different scenarios. But aside from the effect of climate-driven economic change on people’s lives, the change of economy itself cannot be ignored when studying climate and understand possible feedback loops that might or might not lead into local or global catastrophe.
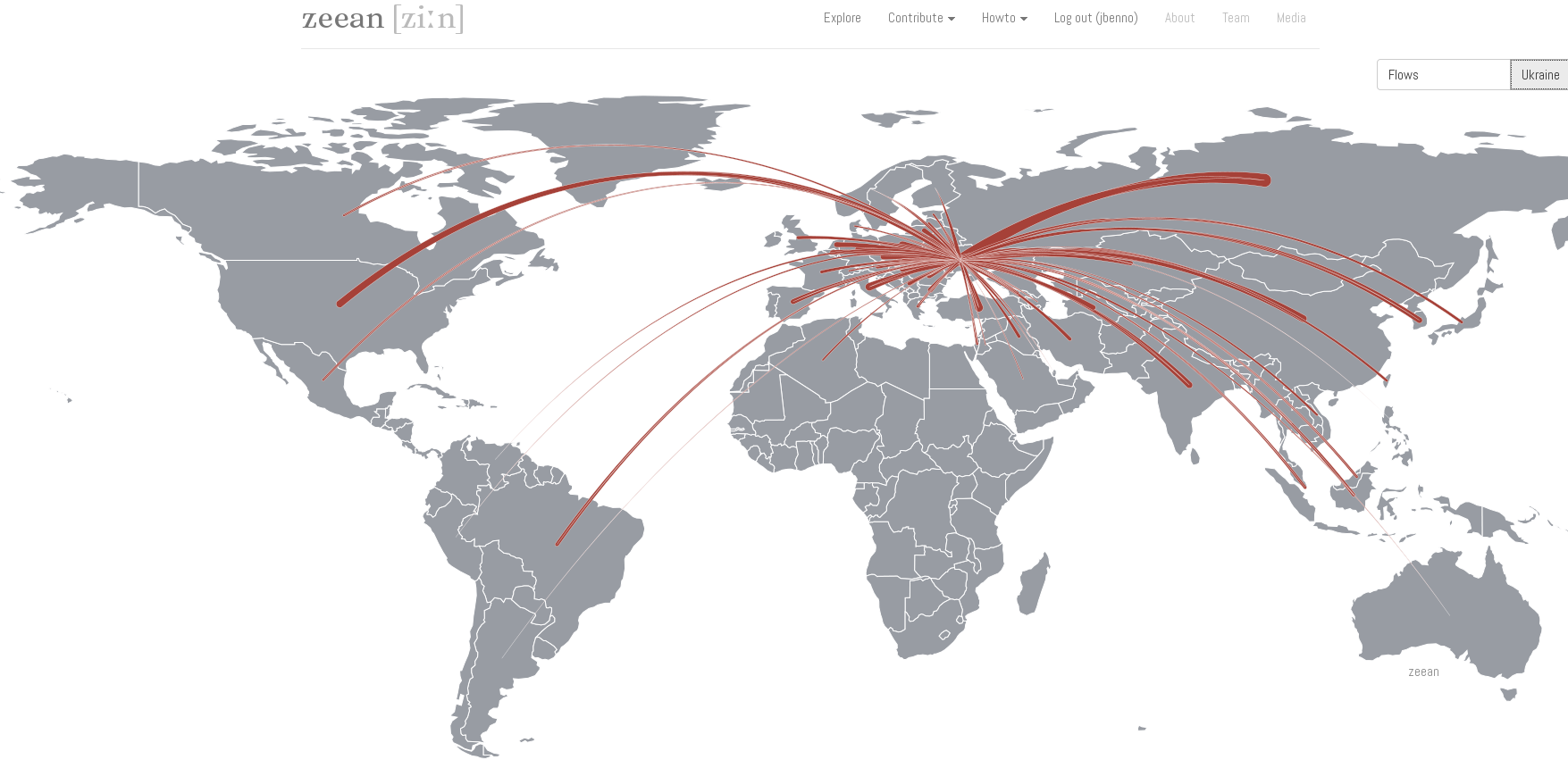
Zeean.net is an open data / open source project aiming at the economic impact of climate change. Collecting data is crowdsourced – everyone can contribute key indicators of geo-economic dependency like interregional and domestic flow of supply and demand in an easy “Wikipedia-like” way. And like Wikipedia, the validation is done by crowd-crosscheck of registered users. Once data is there, it can be fed into simulations. The team behind Zeean, lead by Anders Levermann at Potsdam Institute for Climate Impact Research is directly tied into the Intergovernmental Panel on Climate Change IPCC, leading research on climate change for the UN and thus being one of the most prominent scientific organizations in this field.
So I am looking forward to the data itself being made public (by then brought into a meaningful structure), we could start calculating our own models and predictions, using the powerful open source tools that have been made available during the last years.