“My market research indicates that 50% of your customers are above the median age. But the shocking discovery was that 50% were below the median age.”
(Dilbert; read it somewhere, cant remember the source)
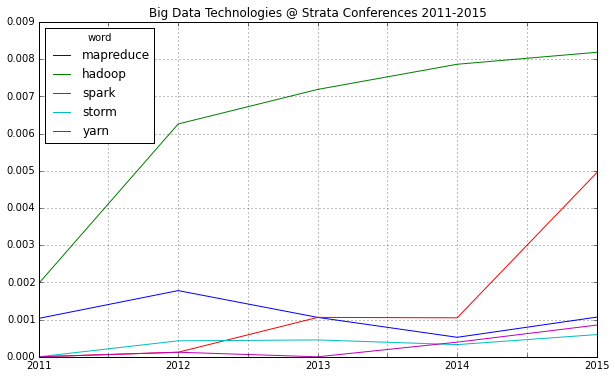
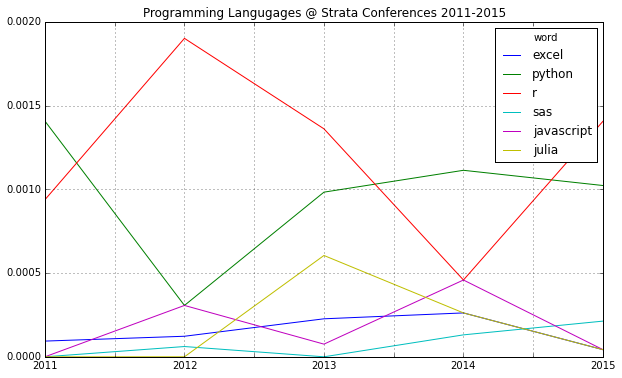
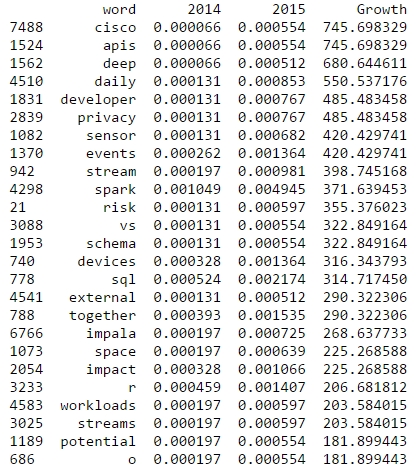
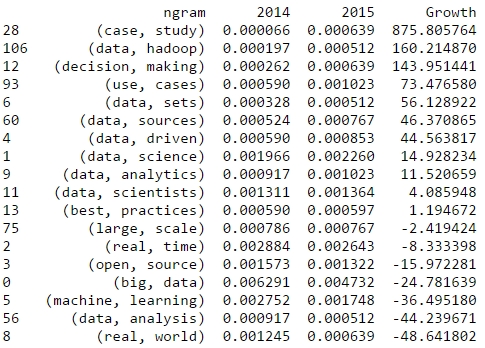
It was funny to see everyone at O’Reilly’s Strata Conference talk about data science and hear just the dinosaurs like Microsoft, Intel or SAP still calling it “Big Data”. Now, for me, too, data science is the real change; and I tell you, why:
What always annoyed me when working with market researchers: you never get an answer. All you get is a description of the sample. Drawing samples was for sure a difficult task 50 years ago. You had to send interviews arround, using a kish grid (does anyone remember this – at least outside Germany?). The data had to be coded into punch cards and clumsy software was used to plot elementary descriptives from ascii-letters. If you still use SPSS, you might know what I am talking about. When I studied statistics in the early 90s, testing hypotheses was much more important than predictions, and visualisaton was not invented yet. The typical presentation of a market researcher would thus start with describing the sample (50% male, 25% from 20 to 39 years, etc.) and in the end, they would leave the client with some more or less trivialy aggregated Excel-Tables.
When I became in charge of pricing ad breaks of a large TV network, all this research was useless for my purposes. My job required predicting the measured audiences of each of the approximately 40 ad breaks for every of our four national stations six weeks in advance. I had to make the decission in real time, no matter how accurate the information I calculated the risks on would have been.
Market research is bad in supporting real time management decissions. So managers tend to decide on their “gut feelings”. But the framework has changed. The last decade brought to us the possibility to access huge data sets with low latency and run highly multivariate models. You cant do online advertising targeting based on gut feelings.
But most market researchers would still argue that the analytics behind ad targeting are not market research because they would just rely on probabilistic decissions, on predictions based on correlations rather than causality. Machine learning does not test a hypothesis that was derived from a theoretical construct of ideas. It identifies patterns and the prediction would be taken as accurate just if the effect on the ROI would be better then before.
I can very well live with the researchers keeping to their custom as long as I may use my data to do the predictions I need. When attending Strata Conference, I realized this deep paradigm shift from market research, describing data as its own end to data science, getting to predicitons.
Maybe it is thus a good thing to differentiate between market research and data science.
(This is the first in a row of posts on our impressions at Strata this year; the others will follow quickly …)