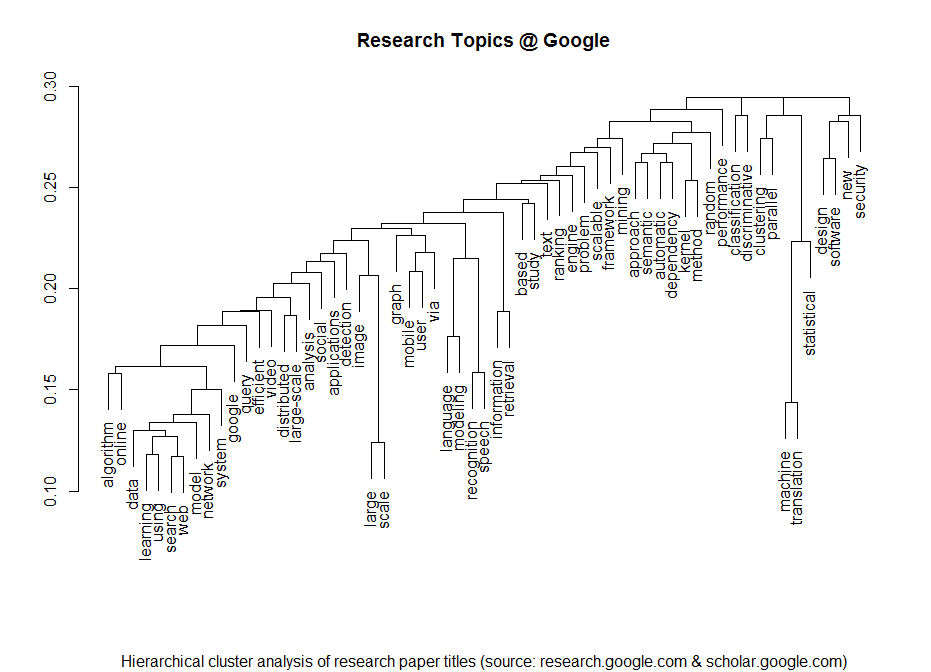
Here’s an updated version of our Big Data Investment Map. I’ve collected information about ca. 50 of the most important Big Data startups via the Crunchbase API. The funding rounds were used to create a weighted directed network with investments being the edges between the nodes (investors and/or startups). If there were multiple companies or persons participating in a funding round, I split the sum between all investors.
This is an excerpt from the resulting network map – made with Gephi. Click to view or download the full graphic:

If you feel, your company is missing in the network map, please tell us in the comments.
The size of the nodes is relative to the logarithmic total result of all their funding rounds. There’s also an alternative view focused on the funding companies – here, the node size is relative to their Big Data investments. Here’s the list of the top Big Data companies:
| Company | Funding (M$, Source: Crunchbase API) |
|---|---|
| VMware | 369 |
| Palantir Technologies | 343 |
| MongoDB, Inc. | 231 |
| DataStax | 167 |
| Cloudera | 141 |
| Domo | 123 |
| Fusion-io | 112 |
| The Climate Corporation | 109 |
| Pivotal | 105 |
| Talend | 102 |
And here’s the top investing companies:
| Company | Big Data funding (M$, Source: Crunchbase API) |
|---|---|
| Founders Fund | 286 |
| Intel | 219 |
| Cisco | 153 |
| New Enterprise Associates | 145 |
| Sequoia Capital | 109 |
| General Electric | 105 |
| Accel Partners | 86 |
| Lightspeed Venture Partners | 72 |
| Greylock Partners | 63 |
| Meritech Capital Partners | 62 |
We can also use network analytical measures to find out about which investment company is best connected to the Big Data start-up ecosystem. I’ve calculated the Betweenness Centrality measure which captures how good nodes are at connecting all the other nodes. So here are the best connected Big Data investors and their investments starting with New Enterprise Associates, Andreessen Horowitz and In-Q-Tel (the venture capital firm for the CIA and the US intelligence community).
| Investor | Centrality | Big Data Companies | |
|---|---|---|---|
| 1 | New Enterprise Associates | 0.0863 | GraphLab, MapR Technologies, Fusion-io, MongoDB, Inc., WibiData, Pentaho, CloudFlare, The Climate Corporation, MemSQL |
| 2 | Andreessen Horowitz | 0.0776 | ClearStory Data, Domo, Fusion-io, Databricks, GoodData, Continuuity, Platfora |
| 3 | In-Q-Tel | 0.0769 | Cloudera, Recorded Future, Cloudant, MongoDB, Inc., Platfora, Palantir Technologies |
| 4 | Founders Fund | 0.0623 | Declara, CrowdFlower, The Climate Corporation, Palantir Technologies, Domo |
| 5 | SV Angel | 0.0602 | Cloudera, Domo, WibiData, Citus Data, The Climate Corporation, MemSQL |
| 6 | Khosla Ventures | 0.0540 | ParStream, Metamarkets, MemSQL, ClearStory Data, The Climate Corporation |
| 7 | IA Ventures | 0.0510 | Metamarkets, Recorded Future, DataSift, MemSQL |
| 8 | Data Collective | 0.0483 | Trifacta, ParStream, Continuuity, Declara, Citus Data, Platfora, MemSQL |
| 9 | Hummer Winblad Venture Partners | 0.0458 | NuoDB, Karmasphere, Domo |
| 10 | Battery Ventures | 0.0437 | Kontagent, SiSense, Continuuity, Platfora |

















")
")
")
{kind=link}