A lot of people still have a lot of respect for Hadoop and MapReduce. I experience it regularly in workshops with market researchers and advertising people. Hadoop’s image is quite comparable with Linux’ perceived image in the 1990s: a tool for professional users that requires a lot of configuration. But in the same way, there were some user-friendly distributions (e.g. Suse), there are MapReduce tools that require almost no configuration.
One favorite example is the ease and speed, you can do serious analytical work on the Google n-grams corpus with Hive on Amazon’s Elastic MapReduce platform. I adapted the very helpful code from the AWS tutorial on the English corpus to find out the trending German words (or 1-grams) for the last century. You need to have an Amazon AWS account and valid SSH keys to connect to the machines you are running the MapReduce programs on (here’s the whole hive query file).
- Start your Elastic MapReduce cluster on the EMR console. I used 1 Master and 19 slave nodes. Select your AWS ssh authorization key. Remember: from this moment on, your cluster is generating costs. So, don’t forget to terminate the cluster after the job is done!
- If your Cluster has been set-up and is running, note the Master-Node-DNS. Open a SSH client (e.g. Putty on Windows or ssh on Linux) and connect to the master node with the ssh key. Your username on the remote machine is “hadoop”.
- Start “hive” and set some useful defaults for the analytical job:
set hive.base.inputformat=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set mapred.min.split.size=134217728;
- The first code snippet connects to the 1-gram dataset which resides on the S3 storage:
CREATE EXTERNAL TABLE german_1grams (
gram string,
year int,
occurrences bigint,
pages bigint,
books bigint
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS SEQUENCEFILE
LOCATION 's3://datasets.elasticmapreduce/ngrams/books/20090715/ger-all/1gram/';
- Now, we can use this database to perform some operations. The first step is to normalize the database, e.g. to transform all words to lower case and remove 1-grams that are no proper words. Of course you could further refine this step to remove stopwords or reduce the words to their stems by stemming or lemmatization.
CREATE TABLE normalized (
gram string,
year int,
occurrences bigint
);
And then we populate this table:
INSERT OVERWRITE TABLE normalized
SELECT
lower(gram),
year,
occurrences
FROM
german_1grams
WHERE
year >= 1889 AND
gram REGEXP "^[A-Za-z+'-]+$";
- The previous steps should run quite fast. Here’s the step that really need to be run on a multi-machine cluster:
CREATE TABLE by_decade (
gram string,
decade int,
ratio double
);INSERT OVERWRITE TABLE by_decade
SELECT
a.gram,
b.decade,
sum(a.occurrences) / b.total
FROM
normalized a
JOIN (
SELECT
substr(year, 0, 3) as decade,
sum(occurrences) as total
FROM
normalized
GROUP BY
substr(year, 0, 3)
) b
ON
substr(a.year, 0, 3) = b.decade
GROUP BY
a.gram,
b.decade,
b.total;
- The final step is to count all the trending words and export the data:
CREATE TABLE result_decade (
gram string,
decade int,
ratio double,
increase double );INSERT OVERWRITE TABLE result_decade
SELECT
a.gram as gram,
a.decade as decade,
a.ratio as ratio,
a.ratio / b.ratio as increase
FROM
by_decade a
JOIN
by_decade b
ON
a.gram = b.gram and
a.decade - 1 = b.decade
WHERE
a.ratio > 0.000001 and
a.decade >= 190
DISTRIBUTE BY
decade
SORT BY
decade ASC,
increase DESC;
- The result is saved as a tab delimited plaintext data file. We just have to find out its correct location and then transfer it from the Hadoop HDFS file system to the “normal” file system on the remote machine and then transfer it to our local computer. The (successful) end of the hive job should look like this on your ssh console:
The line “Deleted hdfs://x.x.x.x:9000/mnt/hive_0110/warehouse/export” gives you the information where the file is located. You can transfer it with the following command:
$ hdfs dfs -cat /mnt/hive_0110/warehouse/export/* > ~/export_file.txt
- Now the data is in the home directory of the remote hadoop user in the file export_file.txt. With a secure file copy program such as scp or WinSCP you can download the file to your local machine. On a Linux machine, I should have converted the AWS SSH key in the Linux format (id_rsa and id_rsa.pub) and then added. With the following command I could download our results (replace x.x.x.x with your IP address or the Master-Host-DNS):
$ scp your_username@x.x.x.x:export_file.txt ~/export_file.txt
- After you verified that the file is intact, you can terminate your Elastic MapReduce instances.
As a result you get a large text file with information on the ngram, decade, relative frequency and growth ratio in comparison with the previous decade. After converting this file into a more readable Excel document with this Python program, it looks like this:
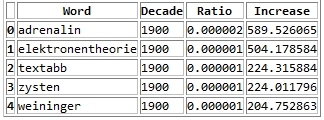
Values higher than 1 in the increase column means that this word has grown in importance while values lower than 1 means that this word had been used more frequently in the previous decade.
Here’s the top 30 results per decade:
- 1900s: Adrenalin, Elektronentheorie, Textabb, Zysten, Weininger, drahtlosen, Mutterschutz, Plazenta, Tonerde, Windhuk, Perseveration, Karzinom, Elektrons, Leukozyten, Housz, Schecks, kber, Zentralwindung, Tarifvertrags, drahtlose, Straftaten, Anopheles, Trypanosomen, radioaktive, Tonschiefer, Achsenzylinder, Heynlin, Bastimento, Fritter, Straftat
- 1910s: Commerzdeputation, Bootkrieg, Diathermie, Feldgrauen, Sasonow, Wehrbeitrag, Bolschewismus, bolschewistischen, Porck, Kriegswirtschaft, Expressionismus, Bolschewiki, Wirtschaftskrieg, HSM, Strahlentherapie, Kriegsziele, Schizophrenie, Berufsberatung, Balkankrieg, Schizophrenen, Enver, Angestelltenversicherung, Strahlenbehandlung, Orczy, Narodna, EKG, Besenval, Flugzeugen, Flugzeuge, Wirkenseinheit
- 1920s: Reichsbahngesellschaft, Milld, Dawesplan, Kungtse, Fascismus, Eidetiker, Spannungsfunktion, Paneuropa, Krestinski, Orogen, Tschechoslovakischen, Weltwirtschaftskonferenz, RSFSR, Sachv, Inflationszeit, Komintern, UdSSR, RPF, Reparationszahlungen, Sachlieferungen, Konjunkturforschung, Schizothymen, Betriebswirtschaftslehre, Kriegsschuldfrage, Nachkriegsjahre, Mussorgski, Nachkriegsjahren, Nachkriegszeit, Notgemeinschaft, Erlik
- 1930s: Reichsarbeitsdienst, Wehrwirtschaft, Anerbengericht, Remilitarisierung, Steuergutscheine, Huguenau, Molotov, Volksfront, Hauptvereinigung, Reichsarbeitsdienstes, Viruses, Mandschukuo, Erzeugungsschlacht, Neutrons, MacHeath, Reichsautobahnen, Ciano, Vierjahresplan, Erbkranken, Schuschnigg, Reichsgruppe, Arbeitsfront, NSDAP, Tarifordnungen, Vierjahresplanes, Mutationsrate, Erbhof, GDI, Hitlerjugend, Gemeinnutz
- 1940s: KLV, Cibazol, UNRRA, Vollziehungsrath, Bhil, Verordening, Akha, Sulfamides, Ekiken, Wehrmachtbericht, Capsiden, Meau, Lewerenz, Wehrmachtsbericht, juedischen, Kriegsberichter, Rourden, Gauwirtschaftskammer, Kriegseinsatz, Bidault, Sartre, Riepp, Thailands, Oppanol, Jeftanovic, OEEC, Westzonen, Secretaris, pharmaceutiques, Lodsch
- 1950s: DDZ, Peniteat, ACTH, Bleist, Siebenjahrplan, Reaktoren, Cortison, Stalinallee, Betriebsparteiorganisation, Europaarmee, NPDP, SVN, Genossenschaftsbauern, Grundorganisationen, Sputnik, Wasserstoffwaffen, ADAP, BverfGg, Chruschtschows, Abung, CVP, Atomtod, Chruschtschow, Andagoya, LPG, OECE, LDPD, Hakoah, Cortisone, GrundG
- 1960s: Goldburg, Dubcek, Entwicklungszusammenarbeit, Industriepreisreform, Thant, Hoggan, Rhetikus, NPD, Globalstrategie, Notstandsgesetze, Nichtverbreitung, Kennedys, PPF, Pompidou, Nichtweiterverbreitung, neokolonialistischen, Teilhards, Notstandsverfassung, Biafra, Kiesingers, McNamara, Hochhuth, BMZ, OAU, Dutschke, Rusk, Neokolonialismus, Atomstreitmacht, Periodikums, MLF
- 1970s: Zsfassung, Eurokommunismus, Labov, Sprechakttheorie, Werkkreis, Uerden, Textsorte, NPS, Legitimationsprobleme, Aktanten, Kurztitelaufnahme, Parlamentsfragen, Textsorten, Soziolinguistik, Rawls, Uird, Textlinguistik, IPW, Positivismusstreit, Jusos, UTB, Komplexprogramms, Praxisbezug, performativen, Todorov, Namibias, Uenn, ZSta, Energiekrise, Lernzielen
- 1980s: Gorbatschows, Myanmar, Solidarnosc, FMLN, Schattenwirtschaft, Gorbatschow, Contadora, Sandinisten, Historikerstreit, Reagans, sandinistische, Postmoderne, Perestrojka, BTX, Glasnost, Zeitzeugen, Reagan, Miskito, nicaraguanischen, Madeyski, Frauenforschung, FSLN, sandinistischen, Contras, Lyotard, Fachi, Gentechnologie, UNIX, Tschernobyl, Beijing
- 1990s: BSTU, Informationsamt, Sapmo, SOEP, Tschetschenien, EGV, BMBF, OSZE, Zaig, Posllach, Oibe, Benchmarking, postkommunistischen, Reengineering, Gauck, Osterweiterung, Belarus, Tatarstan, Beitrittsgebiet, Cyberspace, Goldhagens, Treuhandanstalt, Outsourcing, Modrows, Diensteinheiten, EZB, Einigungsvertrages, Einigungsvertrag, Wessis, Einheitsaufnahme
- 2000s: MySQL, Servlet, Firefox, LFRS, Dreamweaver, iPod, Blog, Weblogs, VoIP, Weblog, Messmodells, Messmodelle, Blogs, Mozilla, Stylesheet, Nameserver, Google, Markenmanagement, JDBC, IPSEC, Bluetooth, Offshoring, ASPX, WLAN, Wikipedia, Messmodell, Praxistipp, RFID, Grin, Staroffice