I am a regular visitor of Google’s research page where they post all of their latest and upcoming scientific papers. Lately I have thought whether it would be possible to statistically extract some of the meta-information from the papers. Here’s the result of the analysis of the papers’ titles produced with just a few lines of R code:
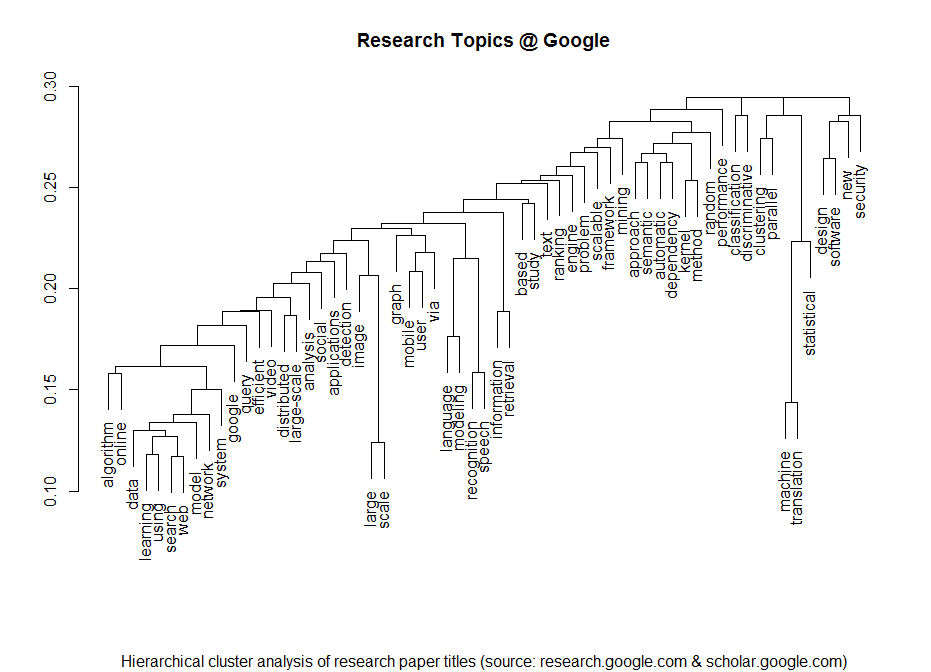
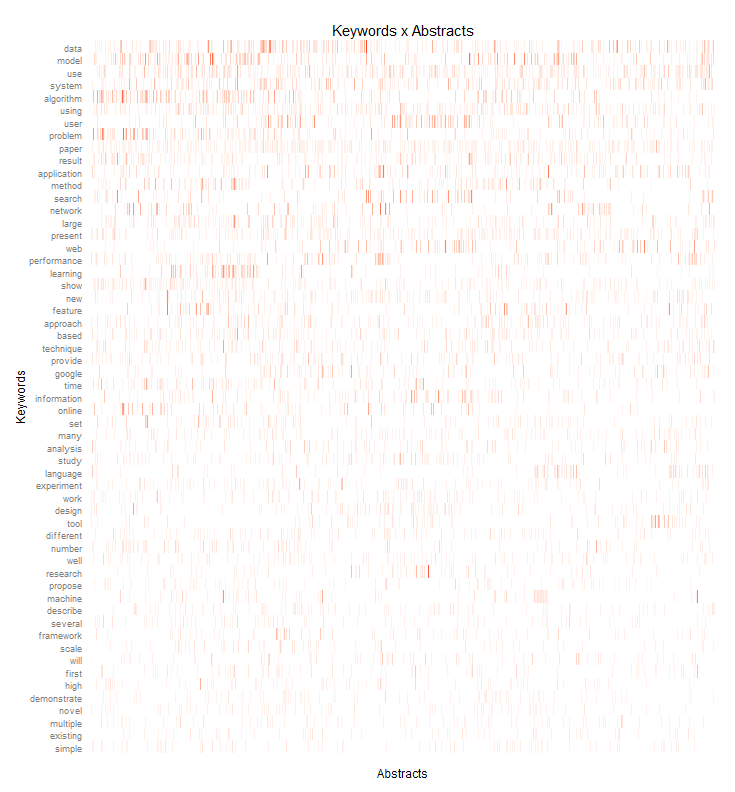
I clustered the data with a standard hierarchical cluster analysis to find out which terms tend to often go together in the paper titles. Then I took a deeper look at the abstracts – of all the papers that had abstracts that is. I processed the abstracts with the tm R package and draw the following heat-map that shows how often which of the most important keywords appear in each paper:
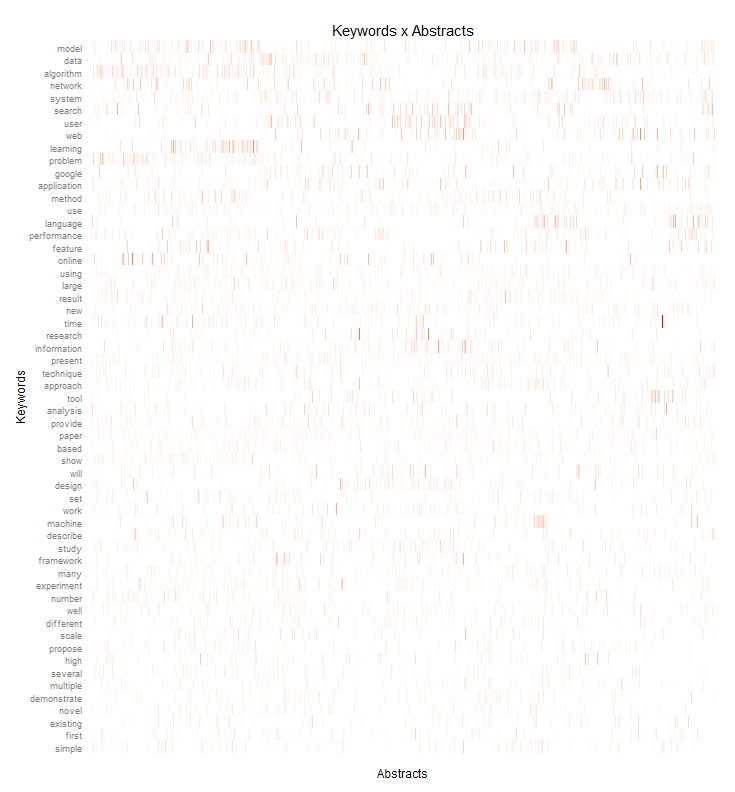
I did a similar heatmap but this time normalized by the term frequency – inverse document frequency measure. While the first heatmap shows the most frequently used terms, this weighted heatmap shows terms that are quite important in their respective research papers but normalizes this by the overall term frequency.
If you need input for playing buzzword bingo at the next Strata Conference in Santa Clara, you don’t have to look any further 😉